Pythonまとめ(openpyxlライブラリ)
エクセル操作(openpyxl)
openpyxlライブラリを使うとエクセルファイルの操作が行える。注意点としてこのライブラリは数式の計算はできない。なのでopenpyxlでデータを更新したとしても、その計算結果をopenpyxlで取得することはできない。それにはopenpyxlでデータの更新だけ行い、再計算はExcelに委ねる。なお、Excelは最後の計算結果を保存しているため、最後にファイルを保存したときの計算結果は取得できる。
本稿では既存のエクセルファイルを単純に読み書きするための操作を中心に記載しており、条件付き書式やビュー、テーブル、チャートなどの項目については記載していない。
クラス構造
openpyxlでは主にWorkbook、Worksheet、Cellの3つのクラスを扱う。エクセルファイルがWorkbook、シートがWorksheet、セルがCellに対応している。
Workbook
エクセルファイルに相当するのがWorkbookである。ファイルをオープンすれば作成される。なお、openpyxlで開いたエクセルをそのまま保存すると一部データが失われることがあるため、別名で保存するが、保存しないで閉じること。
>>> excel = openpyxl.load_workbook(file, data_only=True)
>>> type(excel)
<class 'openpyxl.workbook.workbook.Workbook'>既存のエクセルファイルを開くのではなく、新規に作成するのであれば新規オブジェクトを作成するだけでよい。そうすれば1つのシートを持つWorkbookが作成される。
>>> wb = openpyxl.Workbook()
>>> type( wb )
<class 'openpyxl.workbook.workbook.Workbook'>Workbookの作成・保存
openpyxl.load_workbook関数でエクセルファイルを開き、Workbookオブジェクトを得られる。load_workbookでは引数で以下のオプションを指定できる。
| オプション | 意味 | デフォルト値 |
|---|---|---|
| file | エクセルファイルのパス | |
| read_only | 読み込み専用で開く | False |
| keep_vba | VBAマクロを保持する | False |
| data_only | セルの値として、数式は最後の計算結果を使用する | False |
| keep_links | 他のエクセルへのリンクを保持する | True |
| rich_text | セルのリッチテキスト情報を保持する | False |
保存するにはWorkbook.saveメソッドを使う。繰り返しとなるがopenpyxlではデータが失われることがあるため別名保存を基本としたほうが良い。
| 分類 | 項目 | サンプルコード | 実行サンプル |
|---|---|---|---|
| 保存 | Workbookを保存 | wb.save(r'C:\Users\...') | - |
Workbookの操作
Workbookはファイル全体で共通な情報やワークシートの情報を保持しており、それらを追加や削除するメソッドも提供している。
| 分類 | 項目 | サンプルコード | 実行サンプル |
|---|---|---|---|
| シート関連 | シート名の一覧を取得 | wb.sheetnames | ['Sheet1', 'Sheet2'] |
| シートの一覧を取得 | wb.worksheets | [<Worksheet "Sheet1">,<Worksheet "Sheet2">] | |
| シート名でシートを取得 | wb[ 'Sheet1' ] | <Worksheet "Sheet1"> | |
| アクティブなシートを取得 | wb.active | <Worksheet "Sheet1"> | |
| シートをアクティブにする | wb.active = wb["Sheet2"] | 戻り値なし | |
| シートを追加 | wb.create_sheet( 'Sheet3', 0 )wb.sheetnames | <Worksheet "Sheet3"> | |
| シートを削除 | wb.remove( excel["Sheet2"] )wb.sheetnames | ['Sheet3', 'Sheet1'] | |
| シートのインデックスを取得 | wb.index( excel['Sheet1'] ) | 1 | |
| シートを移動 | wb.move_sheet('Sheet1', -1) | | |
| 名前関連 | 名前の一覧を取得 | wb.defined_names.keys() | ['Name1', 'Name2'] |
| 名前が参照する範囲を取得 | wb.defined_names['Name1'].value | 'Sheet1!$A$11' |
Worksheet
Worksheetではシート個別の情報やシート内のセルを取得するためのメソッドが提供される。
セルアクセス
| 分類 | 項目 | サンプルコード | 実行サンプル |
|---|---|---|---|
| セル関連 | セルを取得1 | ws['A1'] | <Cell 'Sheet3'.A1> |
| セルを取得2 | ws.cell(row=1,column=1) | <Cell 'Sheet3'.A1> | |
| セルに値を設定して取得 | ws.cell(row=2,column=1,value='test') | <Cell 'Sheet3'.A2> | |
| 結合されたセルの一覧を取得 | ws.merged_cells | <MultiCellRange [A11:C11 D11:E13]> | |
| 行・列関連 | 有効な範囲のセルを取得 | ws.rows # 行単位の操作用※データのない範囲のセルはこれでは取得できない | generator object |
| 空行を追加 | ws.insert_rows( 2, 3) # 2行目の上に空行を3行追加 | - | |
| 行を削除 | ws.delete_rows( 2, 3) # 2行目から3行を削除 | - | |
| 空の列を追加 | ws.insert_cols( 2, 3) # 2列目の左に列を3列追加 | - | |
| 列を削除 | ws.delete_cols( 2, 3) # 2列目から3列を削除 | - | |
| 範囲操作 | 指定範囲のセルを取得 | # 以下はどちらもC1:D5を取得する。並びが行基準か列基準かの違いのみws.iter_rows(min_row=1, max_row=5, min_col=3, max_col=4) | generator object |
| 指定範囲のセルの値を取得 | # 以下はどちらもC1:D5を取得する。並びが行基準か列基準かの違いのみws.iter_rows(min_row=1, max_row=5, min_col=3, max_col=4, values_only=True) | generator object |
Cell
Cellではそのセルの座標や値に関する情報を取得できる。
| 分類 | 項目 | サンプルコード | 実行サンプル |
|---|---|---|---|
| 値関連 | セルの値を取得 | cell.value | 2023-08-11戻り値はstr,int,float,datetime,time,bool,Noneのいずれか |
| セルに値を設定 | cell.value = 'newvalue' | - | |
| セルの値の種別 | cell.data_type | n : 数字(または空) s : 文字列 b : 論理値 f : 数式 e : エラーコード | |
| 座標関連 | セルの座標を取得 | cell.coordinate | C3 |
| セルの行番号、列番号を取得 | cell.row | 3 | |
| セルの列名を取得 | cell.column_letter | C | |
| その他 | シートを取得 | cell.parent | <Worksheet "Sheet1"> |
| 相対位置にあるセルを取得 | cell.offset(2,3)# 今のセルから2行下、3行右のセル | <Cell 'Sheet1'.E5> | |
| コメントを取得 | cell.comment | Comment型 |
ユーティリティ
エクセル操作に役立つユーティリティも用意されている。以下のソッドはいずれもopenpyxl.utils.cellモジュールにありインポートが必要である。
| 項目 | サンプル | 実行例 |
|---|---|---|
| セル範囲文字列をバウンダリを表すタプルに変換 | range_boundaries('A3') | (1, 3, 1, 3) |
| セル範囲文字列をセル座標のタプルに変換 | | # ジェネレータが得られる。以下は出力例 |
| セル参照文字列をタプルに変換 | range_to_tuple('sheet1!A3:C5') | ('sheet1', (1, 3, 3, 5)) |
| 列番号の変換 | get_column_letter(3) | 'C' |
| 列名の変換 | column_index_from_string('C') | 3 |
| 列範囲の変換 | get_column_interval(3,5) | ['C', 'D', 'E'] |
サンプル
いくつかエクセル操作のサンプルを示す。
単純なデータの読み込み
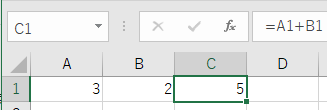
| フラグ | date_only=False | date_only=True |
|---|---|---|
| サンプル | import openpyxl | import openpyxl |
| 実行結果 | =A1+B1 | 5 |
指定範囲の参照
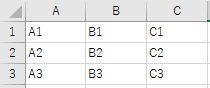
import openpyxl
wb = openpyxl.load_workbook(file)
ws =wb['Sheet1']
for row in ws.iter_rows(1,3,1,3):
for cell in row:
print( cell.value, end="")
print()A1B1C1
A2B2C2
A3B3C3全データの処理
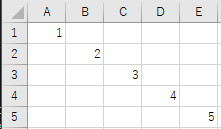
import openpyxl
wb = openpyxl.load_workbook(file)
ws = wb['Sheet1']
for rowvalues in ws.values:
print( rowvalues )(1, None, None, None, None)
(None, 2, None, None, None)
(None, None, 3, None, None)
(None, None, None, 4, None)
(None, None, None, None, 5)空白セルのvalueにはNoneが入っている。Noneを手軽に空文字列にしたいならcell.value or ''でできる。ただし、これは論理値Falseが入っているときも空文字になるため、論理値が入っていない前提のときに使うか、cell.value if cell.value is not None else ''のようちゃんとチェックする。
様々なデータのタイプ
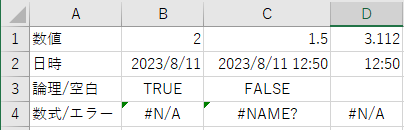
B4,C4には数式が入っており、D4は文字列#N/Aが入っている
import openpyxl
wb = openpyxl.load_workbook(file)
ws = wb['Sheet1']
for row in ws:
for cell in row:
print(f"{cell.value} {type(cell.value).__name__} {cell.data_type}")
print()| 項目 | data_only=False | data_only=True |
|---|---|---|
| 数値 | 2 int n 1.5 float n 3.112 float n | 2 int n 1.5 float n 3.112 float n |
| 日時 | 2023-08-11 00:00:00 datetime d 2023-08-11 12:50:00 datetime d 12:50:00 time d | 2023-08-11 00:00:00 datetime d 2023-08-11 12:50:00 datetime d 12:50:00 time d |
| 論理/空白 | True bool b False bool b None NoneType n | True bool b False bool b None NoneType n |
| 数式/エラー | =MATCH("5",B1:D1) str f =NA str f N/A str e | N/A str e NAME? str e N/A str e |
エラーは単なる文字列であり、data_typeではエラーの文字列と一致しているか見ているだけなので、D4の文字列#N/Aもエラーとして判定される。
