Pythonまとめ(1.基本構文)
本記事は筆者が業務自動化などでたまに使うPythonを、すぐ思い出せるようにポイントをまとめたものです。初学者がわかりやすいように、あるいは正確で十分な記載になるようにという観点ではまとめていないため、ちゃんと学習したい方は他のサイトをご利用ください。
表記ルール
プログラムコードは以下のように原則としてブロックで示す。ただし、文や表の中などはpython codeのように記す。
python code
実行結果がある場合は水色のブロックで示す。
出力結果プログラムコードの中には対話モードで実行することを想定したものが含まれる。その場合は以下のように示す。行頭が「>>>」であればコマンド行であり、「...」は上の行のコマンドが継続していることを示す。行頭に何もない行は実行結果である。
def method(): # コマンド行
(con) print(1) # コマンド継続行
(con) # コマンド継続行
method() # コマンド行
(out)1 # 実行結果
基本構文
変数の宣言
変数とは何らかの値と名前を関連付けて保存するものである。Pythonでは宣言や定義することなく変数を使用できる。もし初期化されていない変数を使おうとするとUnboundLocalErrorやNameErrorが発生する。
varname = "値" # これにより変数varnameは値を参照するように初期化される
print( varname ) # これは初期化されている変数をしようしているため問題なし
(out)"値"
print( nonename ) # nonenameは初期化されていない変数のためエラーが発生する
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)NameError: name 'nonename' is not defined
データ型
データ型とは変数が参照しているデータの種類のことである。Pythonは動的型付けに分類されるプログラミング言語であり、変数の型は実データが代入されたときに決定する。そのためVisual Studioのような開発環境では変数の型を推定して開発支援を行う。たとえばvariable = "string"というコードからは変数variableが文字列であることが推定できる。そうするとvariableが文字列であるとして、文字列で使用可能なメソッド候補を表示したりできる。
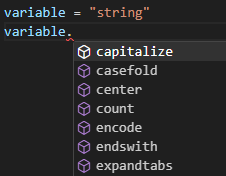
しかし、場合によっては推定が十分に行えないことがある。その場合は型ヒントを記載することで開発環境やコンパイラに対して変数の型のヒントを与えることが出来る。当然ながらこの型ヒントは開発者にとっても意味のあるものとなる。
型ヒントの記載方法として型アノテーションが使用できる。詳細は型ヒントの項目を参照すること。この型アノテーションはいわば型に関するコメントであり、プログラムの動作には影響しない。
varname:str = "value"
関数の定義
関数は入力を受け取り、何らかの処理を行い、結果を出力する処理のかたまりである。Pythonにおいて関数を定義するにはdefを使う。プログラムにおいて関数の入力を引数、出力は戻り値と呼ぶ。
def 関数名(引数名1, 引数名2, ...):
関数の処理
return 戻り値
なお、型アノテーションをつけると以下のようになる。
def 関数名(引数名1:引数名1の型, 引数名2:引数名2の型, ...) -> 戻り値の型:
関数の処理
return 戻り値
引数
仮引数と実引数
引数について仮引数と実引数という2つの用語が使い分けられることがある。仮引数とは関数を定義するときに引数部分に書く変数のことであり、実引数とは仮引数に代入される具体的な値のことである。英語ではそれぞれparameter(仮引数)とargument(実引数)と呼ばれる。英語の方が分かりやすいだろう。
和を求める関数sumで2つの違いを見る。
def sum(a:int, b:int) -> int:
return a+b
この関数定義の引数a、bは変数であり、どちらも関数が呼びだれるときに具体的な値が決まる。これがパラメータ、すなわち仮引数である。次にこのsum関数を呼び出す。
sum(4, 5)
このsum関数に渡された引数の値4、5は仮引数に代入される具体的な値であり実引数である。
デフォルト値
仮引数のデフォルト値を指定することができる。デフォルト値がある仮引数は呼び出し時に省略できる。以下の例であればfunction_name(10)でも呼び出すことができる。
def function_name(arg1, arg2 = default2, arg3 = default3, ... ):
関数の処理
デフォルト値を持つ仮引数の後に、デフォルト値を持たない仮引数を定義することはできない。以下のようなエラーとなる。
def invalid_method(arg1, arg2="", arg3):
(out) File "", line 1
(out) def illegal_method(arg1, arg2="", arg3):
(out) ^^^^
(out)SyntaxError: parameter without a default follows parameter with a default
位置引数とキーワード引数
Pythonでは実引数を指定するときに、仮引数の定義順に書く方法(位置引数)と仮引数の名前を指定して書く方法(キーワード引数)の2つがある。デフォルトでは引数は位置引数とキーワード引数の両方として振る舞うことができる。
def checksum(value1, value2, sum):
(con) return value1+value2 == sum
上のような、3つの引数を持つ関数で考えてみる。この関数はvalue1とvalue2の和がsumになるかチェックする関数である。
この場合、一番シンプルな実引数の指定方法は以下のように仮引数の定義通りに書く方法である。これが位置引数である。
checksum(2,5,6) # Check if 2+5 equal 6
(out)False
checksum(2,5,7) # Check if 2+5 equal 7
(out)True
キーワード引数を使うと以下のように、定義された順番を無視して書くことができる。
checksum(sum=10,value1=3,value2=7) # Check if 3+7 equal 10
(out)True
位置引数とキーワード引数を混在させてもよい。キーワード引数は位置を無視して値を渡す方法であるため、位置引数とキーワード引数を混在させるときには、位置引数よりキーワード引数が先にくる。
checksum(3, sum=7, value2=4) # Check if 3+4 equal 7
(out)True
この例では特に混在する意味は無いが、必須パラメータを位置引数として渡し、オプションのパラメータをデフォルト値のあるキーワード引数として渡させるような使い方をする。
位置専用引数とキーワード専用引数
デフォルトでは位置引数・キーワード引数の両方で値を渡すことができるが、どちらか一方でのみ値を渡せる引数も作成できる。関数の定義において/の前に定義された引数は位置引数としてしか値を渡せない位置専用引数となり、キーワードを指定して引数を渡すことはできない。*の後に定義された引数はキーワード専用引数となり、位置で引数を渡すことはできない。
def method(位置専用引数, /, 標準の引数(位置引数でもキーワード引数でも可), *, キーワード専用引数):
関数の処理
以下のような3つの値を加算する関数で専用引数の例をみてみる。
def sum3(arg1, /, arg2, *, arg3):
(con) return arg1+arg2+arg3
この関数ではarg1は位置引数として、arg3はキーワード引数として値を渡さなければならない。arg2はどちらでも良い。
sum3(1, arg2=2, arg3=3)
(out)6
sum3(1, 2, arg3=3)
(out)6
それ以外の方法で値を渡そうとするとエラーになる。
sum3(1, 2, 3)
(out)TypeError: argtest() takes 2 positional arguments but 3 were given
(out)※エラーメッセージ訳:argtest()には位置引数が2つあるが3つ指定された
sum3(arg1=1, arg2=2, arg3=3)
(out)TypeError: argtest() got some positional-only arguments passed as keyword arguments: 'arg1'
(out)※エラーメッセージ訳:argtest()の位置専用引数の一部がキーワード引数として渡された:'arg1'
可変長引数
仮引数に*または**をつけることで可変長の引数を受け取ることができる。*は位置引数で可変長の引数を受け取るときに使い、値はタプルになる。**はキーワード引数で可変長の引数を受け取るときに使い、値は辞書になる。キーワード引数の制約により両方を併用するときは*より**の方が後にくる。
def printtest(arg1, *arg2, **arg3):
(con) print(f" ARG1:{arg1}")
(con) print(f" *ARG2:{arg2}")
(con) print(f"**ARG3:{arg3}")
(con)
printtest( "引数1", "引数2", "引数3", "引数4", "引数5", Arg6="引数6", Arg7="引数7")
(out) ARG1:引数1
(out) *ARG2:('引数2', '引数3', '引数4', '引数5')
(out)**ARG3:{'Arg6': '引数6', 'Arg7': '引数7'}
可変長引数とデフォルト値
可変長引数はデフォルト値があるものとして扱われる。空のタプルか空の辞書となる。以下のコードはエラーなく動作する。
def functest(arg1="", *arg2):
pass
可変長引数とキーワード専用引数
位置引数の可変長引数は位置引数の最後となり、それ以降はキーワード専用引数となる。そのためキーワード専用引数を明示的に指定しようとするとエラーになる。
def functest(*arg, keyarg1): # OK。keyarg1は位置専用引数
(con) pass
(con)
def functest(*arg, *, keyarg1):
(out) File "<stdin>", line 1
(out) def functest(*arg, *, keyarg1):
(out) ^
(out)SyntaxError: * argument may appear only once
値渡しと参照渡し
プログラムにおいて関数に値を渡す一般的な方法に値渡しと参照渡しがある。値渡しは値のコピーを関数に渡すものであり、関数側で値を変更しても呼び出し側に影響を与えることはない。参照渡しは値の場所を関数に渡すものであり、関数側で値を変更すると呼び出し側にも影響を与える。
Pythonにおいては値渡しが使われるが、値として渡されるのは参照である。これを「オブジェクトへの参照渡し」と呼ぶ。Pythonでは参照渡しそのものはできない。
- 関数側で渡されたオブジェクトに変更を加えた場合、呼び出し側にも影響を与える。ただし、そのオブジェクトがイミュータブルである場合は除く。
- 関数側で渡されたオブジェクトに別のオブジェクトを代入をした場合、呼び出し側には影響を与えない。
シャローコピーとディープコピー
値を参照で渡すが故に、呼び出し側で同じ場所を参照している変数に影響を与える。この影響を避ける必要があるときにはオブジェクトを複製し、複製した値の参照を関数に渡す。影響を完全に排除するためにはディープコピーという複製方式を選択する必要がある。ディープコピーの対となるものをシャローコピーという。
シャローコピーとディープコピーの詳細
オブジェクトが参照渡しによる影響を受けないようにするには、オブジェクトをコピーし、コピーしたオブジェクトを関数に渡す。
2×2の行列を書き換える関数でオブジェクトのコピーについて考える。
def updatelist(datas):
(con) datas[0][1] = 6
(con) datas[1] = [7,8]
(con)
list1 = [[1,2], [3,4]]
list2 = list1
updatelist(list2)
list1
(out)[[1, 6], [7, 8]]
変数list1を他の変数list2に代入し、list2をupdatelist関数に渡している。代入文list2 = list1はlist2とlist1が同じオブジェクトを参照するというものであり、list2を更新すればlist1も影響を受ける。このプログラムがlist1の元の値を残しておきたいという意図でlist2にlist1を代入したのであれば、意図したとおりに動作しないため不具合である。
改善案として別のオブジェクトlist2を作成し、list2に値をコピーするように修正してみる。
list1 = [[1,2], [3,4]]
list2 = []
for row in list1:
(con) list2.append(row)
(con)
list2
(out)[[1, 2], [3, 4]]
updatelist(list2)
list1
(out)[[1, 6], [3, 4]]
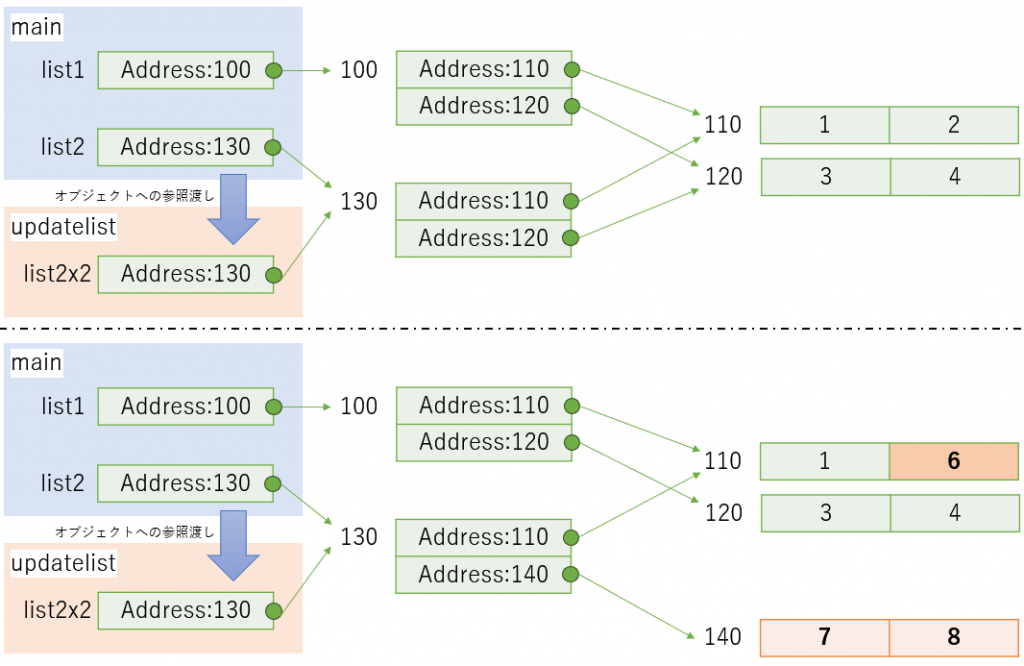
この実装でもlist1がupdatelistによる更新の影響を受けている。これはlist2の中身にlist1の元オブジェクトへの参照を含んでいるためである。このような元のオブジェクトへの参照を含むようなコピーをシャローコピー(浅いコピー)とよぶ。シャローコピーではコピー先を変更したときにコピー元のオブジェクトに影響を与えることがある。サンプルにおけるシャローコピーのイメージは下図のとおりである。
list1に一切の影響を与えないように修正を加えると以下の通りとなる。
list1 = [[1,2], [3,4]]
list2 = []
for row in list1:
(con) temp = []
(con) for item in row:
(con) temp.append(item)
(con) list2.append(temp)
(con)
list2
(out)[[1, 2], [3, 4]]
updatelist(list2)
list2
(out)[[1, 6], [7, 8]]
list1
(out)[[1, 2], [3, 4]]
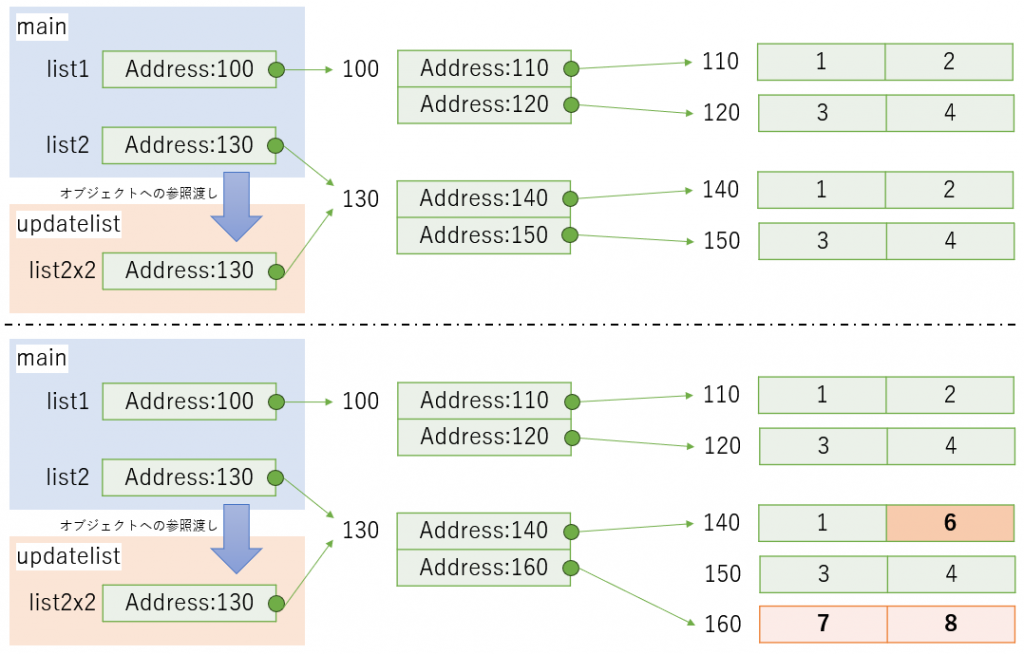
list2を新しいオブジェクトとして作成し、その中身も1つずつコピーしている。この場合はupdatelistによる更新はlist1へ影響を与えない。このように完全に別物としてコピーすることをディープコピー(深いコピー)という。サンプルにおけるディープコピーのイメージ図は下図のとおりとなる。
この例では2x2のリストという前提であるが、様々なオブジェクトをコピーしたいことがある。そのような場合にはcopyライブラリのcopy.deepcopy()が便利である。
戻り値
処理結果を呼び出し元に渡すときはreturnを用いる。returnで値が指定されない場合や、return文無しで関数が終了した場合はNoneが返される。
def methodtest1(arg1, arg2):
(con) return arg1+arg2
(con)
def methodtest2():
(con) pass
(con)
methodtest1(3,5)
(out)8
methodtest2()
methodtest2() is None
(out)True
ラムダ式
ラムダ式は名前を持たない小さな関数である。無名関数とも呼ばれる。関数を渡す必要があるが、単純な処理であったり、1度だけ使わないような処理であったり、関数を作るまでもない場合などに使用される。
lambda arguments: expression以下に2つの引数を持ち、その和を求めるラムダ式を使う例を示す。
def executefunc(func, *args, **keyargs):
(con) return func(*args, *keyargs)
(con)
executefunc(lambda x,y: x+y, 1, 2)
(out)3
標準入出力
標準出力
標準出力に表示するにはprint関数を使う。デフォルトでは出力後に改行される。
print('print data')
(out)print data
printは出力する対象を任意の個数受け取ることができる。デフォルトでは各データの間には空白が入れられる。
print('data1', 'data2', 'data3')
(out)data1 data2 data3
与えられたデータがstrでない場合、str()関数により文字列に変換されて出力される。どのように表示されるかは各オブジェクトの実装に依存する。
print関数の定義
print関数は以下のように定義される。
print( *objects, sep=' ', end='\n', file=sys.stdout, flush=False)| キーワード名 | デフォルト値 | 意味 |
|---|---|---|
| sep | 半角空白 | 出力内容が複数指定されたときの区切り文字 |
| end | \n | 出力終了後に出力する文字。改行しないようにするには""を指定する。 |
| file | None | 出力先。write(string)メソッドを持つオブジェクト。Noneの場合はsys.stdout |
| flush | False | Trueの場合、出力後に強制的にフラッシュする(バッファから出力先へ書き出す)。 |
print('data', end="")
(out)data>>>
標準入力
標準入力から読み込むにはinput関数を使う。引数promptがあると、promptを表示した後に標準入力からの待機状態になる。
input()
input(prompt)以下に例を示す。
s = input("Enter your ID:")
(out)Enter your ID:123456789
s
(out)'123456789'
条件分岐
if、elif、elseを用いて条件に応じた処理を行う。
if condition1:
condition1がTrueの場合
elif condition2:
condition1がFalseかつcondition2がTrueの場合
else:
すべてのconditionがFalseの場合condition
conditionにはbool型と呼ばれる真(True)、偽(False)を表すオブジェクトを指定する。bool型が期待される場所でオブジェクトが指定されると、オブジェクトはbool型に変換される。以下のオブジェクトがFalseとして扱われる。
- None
- 数値型において0に相当するもの(0.0やDecimal(0)などを含む)
- コレクションにおいて空であるもの
- 空文字列("")を含む
比較演算子
比較演算子は2つのオブジェクトを比較し、論理値を返す演算子である。オブジェクトによって小さい、大きいの定義は異なることがある。また異なるオブジェクト同士では比較できない場合がある。
| 比較 | 演算子 | サンプル |
|---|---|---|
| 等しい | == | 10 == 20 |
| 等しくない | != | 10 != 20 |
| より小さい(未満) | < | 10 < 20 |
| より大きい(超) | > | 10 > 20 |
| 以下 | <= | 10 <= 20 |
| 以上 | >= | 10 >= 20 |
| 含む | in | 10 in (10,20,30) |
| 含まない | not in | 40 not in (10,20,30) |
| 同じオブジェクト | is | a is b |
| 同じオブジェクトでない | is not | a is not b |
これらの演算子はつなげて書ける。
10 < 20 <= 40 > 30 != 50
(out)True
10 in (10,20,30) not in ((10,20),(20,30),10,20,30)
(out)True
a = 10
b = 20
a is a is not b
(out)True
0 < a in (10,20,30)
(out)True
反復処理
while
条件を満たす間だけ繰り返す反復処理はwhileを使う。
while condition:
条件を満たす間、繰り返す処理条件を満たす間だけ繰り返す反復処理はwhileを使う。
do...while
このwhile文は最初に条件を満たすかチェックするため、一度も処理が実行されないこともある。言語によっては必ず1回は実行するdo...whileがある。Pythonにはdo...whileはないため、後述のbreakを使うなどの方法をとる。
while True:
最低1回は実行する処理
if condition:
breakfor
forはシーケンスなどIterableなオブジェクトに対する反復処理を表す。
for varname in iterable:
各要素に対して順番に実行する処理回数を指定した処理を行う場合はrange関数と併用する。range関数は指定した範囲の整数を表すオブジェクトを返す関数である。たとえばrange(5)は (0,1,2,3,4)、range(3,6)は (3,4,5)となる。
for varname in range(times):
times回実行する処理for varname in range(start, end):
end-start回実行する処理反復処理の途中終了
break
forまたはwhileの中でbreakに到達すると、現在の反復処理を完全に終了し、反復処理の後に続く処理に移る。
a = 0
while True:
(con) a += 1
(con) if a > 3:
(con) break
(con) print(a)
(con)
(out)1
(out)2
(out)3
この例ではwhile True:となっている無限ループである。しかしa>3のときにbreakに到達するようになっており、そこで反復処理が終了する。
continue
forまたはwhileの中でcontinueに到達すると、現在の反復処理を終了し、次の値の反復処理から再開する。
a = 0
while a < 5:
(con) a += 1
(con) if a < 3:
(con) continue
(con) print(a)
(con)
(out)3
(out)4
(out)5
この例ではaが0から5に達するまで繰り返され、値を表示するプログラムである。しかしa<3のときはcontinueに到達するようになっており、6行目のprint(a)は実行されることなく反復処理の最初から再開される。
反復終了後の処理
forまたはwhileにelseがついている場合、そのブロックはループがbreakすることなく終了した場合に実行される。これにはループが1回も実行されなかった場合も含まれる。
以下に数値のリストの中に負の値が含まれるかを表示する例を示す。
def find_negative(*numbers):
(con) for n in numbers:
(con) if n < 0:
(con) print(f"found:{n}")
(con) break
(con) else:
(con) print('not found')
(con)
(out)
find_negative(4,5,-3,5,-9)
(out)found:-3
(out)
find_negative(2,6,5,6)
(out)not found
負の値があるとbreakに到達し、ループが途中終了する。この場合はelseのブロックは実行されない。負の値がない場合はループが最後まで処理するため、elseのブロックが実行される。
pass
何もしない文。構文規則上で文が必要だが、処理することがないときに使う。
パターンマッチ(match...case)
上から順にパターンを評価し、最初にマッチした処理を実行する。_(アンダーバー)はすべてに一致する。この構文はPython 3.10から導入されたため古いバージョンでは動作しない。
match x:
case 1:
xが1のときの処理
case 2:
xが2のときの処理
case _:
xが1でも2でもないときの処理switchとの違い
C言語などでswitch…caseを使ったことがある人は、break文がないことに注意。Pythonでは最初に一致したcaseの処理が実行された後に、後続のcaseが実行されることはない。
or条件
|でパターンをOR条件で複数指定できる。
match x:
case 1|2|3:
xが1か2か3のときの処理
case _:
それ以外のときの処理追加条件(ガード)
パターンが一致し、かつif条件を満たす場合にマッチしたとみなすことができる。
match x:
case 1 if y == True:
xが1かつyがTrueのときの処理
case 1|2:
xが1または2のときの処理コレクションのパターンマッチ
リストやタプル
マッチする対象がリストやタプルの場合、要素ごとにパターンマッチできる。要素ごとに|(OR指定)や_(無条件一致)を指定できる。要素数も一致する必要がある。
match ["a", 200, 30]:
(con) case 'a'|'b', 100, 10|20:
(con) print( 'pattern 1' )
(con) case 'a', 100|200, 30:
(con) print( 'pattern 2' )
(con) case 'b', 100, _:
(con) print( 'pattern 3' )
(con) case 'b', 200, _:
(con) print( 'pattern 4' )
(con)
(out)pattern 2
可変長のシーケンスマッチ
case _,_:と指定すると長さが2のシーケンスにのみマッチする。可変長引数と同じように*をつけることで可変長のリストにマッチさせることができる。一部の要素でパターンマッチをしたいが、要素数は問わない場合に利用できる。
match [1,2,3,4]:
(con) case 1,2,_: # 長さが違うのでマッチしない
(con) print("1,2,_")
(con) case 1,2,*_: # これにはマッチする
(con) print("1,2,*_")
(con)
(out)1,2,*_
後述のキャプチャとも併用できる。複数の引数を受け取る命令文を解析する例を示す。
values = "drop table customer price".split(" ")
print(values)
(out)['drop', 'table', 'customer', 'price']
match values:
(con) case "drop","table",*tablenames:
(con) print("==drop table==")
(con) for table in tablenames:
(con) print(table)
(con)
(out)==drop table==
(out)customer
(out)price
なおcase _:は長さが1以外のリストやタプルにもマッチする。タプルの各要素にマッチするのではなく、タプル全体にマッチすると考えれば良い。
辞書(マッピング)のパターンマッチ
辞書ではキーに対応する値が一致するかでパターンマッチできる。値をアンダーバーにするとキーが存在するかでマッチする。指定されなかったキーはマッチ対象とならない。
def matchtest(dict1):
(con) match dict1:
(con) case {"TYPE":0}: # キーTYPEの値が0であること
(con) print("pattern 1")
(con) case {"ID":_, "NAME":_}: # キーIDとNAMEが存在すること
(con) print("pattern 2")
(con) case {"ID":_}: # キーIDが存在すること
(con) print("pattern 3")
(con) case _:
(con) print('error')
(con)
matchtest( {"TYPE":0, "ID":100} ) # Pattern 1
(out)pattern 1
matchtest( {"TYPE":1, "ID":10, "NAME":"test"} ) # Pattern 2
(out)pattern 2
matchtest( {"TYPE":2, "ID":20, "NOTE":"test"} ) # Pattern 3
(out)pattern 3
matchtest( {"TYPE":2, "NAME":"test", "NOTE":"test"} ) # Pattern error
(out)error
キャプチャパターン
マッチした値を名前に関連付け、caseの中で参照できる。これをキャプチャと呼び、caseで名前を指定することで実現できる。
match [1, 1, 5]:
(con) case 1, 1, x: # これは3つ目の値は何でもよく、その値をxにキャプチャするという意味になる
(con) print( f'pattern 1 and {x=}' )
(con) case x: # これはすべてのオブジェクトにマッチし、その値をxにキャプチャという意味になる
(con) print( f'pattern 2 and {x=}' )
(con)
(out)pattern 1 and x=5
値に条件がある場合はasを使う。
def matchtest(list1):
(con) match list1:
(con) case 1, 0, 1|2|3 as z:
(con) print( f'pattern 1. {z=}' )
(con) case 1, 0, z:
(con) print( f'pattern 2. {z=}' )
(con) case [0, *y] as z:
(con) print( f'pattern 3. {y=}, {z=}' )
(con) case z:
(con) print( f'pattern 4. {z=}' )
(con)
matchtest( [1, 0, 1] )
(out)pattern 1. z=1
(out)
matchtest( [1, 0, 5] )
(out)pattern 2. z=5
(out)
matchtest( [0, 9, 4] )
(out)pattern 3. y=[9, 4], z=[0, 9, 4]
(out)
matchtest( [1,-3, 5] )
(out)pattern 4. z=[1, -3, 5]
(out)
定数や変数とのパターンマッチ
変数の値とパターンマッチさせようとしてcaseに変数名を指定するとキャプチャパターンとみなされてしまう。しかし.を含む名前はキャプチャパターンとみなされないため、Enumなどの定数とパターンマッチできる。
values = [1,2,3,4]
class Number():
(con) A:int = 1
(con) B:int = 2
(con)
for value in values:
(con) print(f"{value}:", end="")
(con) match value:
(con) case Number.A:
(con) print("A")
(con) case Number.B:
(con) print("B")
(con) case _:
(con) print("_")
(con)
(out)1:A
(out)2:B
(out)3:_
(out)4:_
クラスパターンマッチ
任意のクラスともパターンマッチできる。caseでクラス名と属性の値を指定する。たとえばcase Point(x=0, y=_)と指定した場合、マッチ対象のオブジェクトは以下のように検査される。
- オブジェクトはPointまたはその派生型であるか(
isinstance(obj, Point)がTrueとなるobjか) - オブジェクトはxアトリビュートを持ち、その値が0であるか
- オブジェクトはyアトリビュートを持っているか
座標を表すPointクラスでパターンマッチする例を示す。
from abc import ABC, ABCMeta, abstractmethod
class Point(metaclass = ABCMeta):
(con) @abstractmethod
(con) def coordinate(self):
(con) pass
(con)
class Point1D(Point):
(con) def __init__(self, x=0):
(con) self.x = x
(con)
(con) def coordinate(self):
(con) return [self.x]
(con)
class Point2D(Point):
(con) def __init__(self, x=0, y=0):
(con) self.x = x
(con) self.y = y
(con)
(con) def coordinate(self):
(con) return [self.x, self.y]
(con)
class Point3D(Point):
(con) def __init__(self, x=0, y=0, z=0):
(con) self.x = x
(con) self.y = y
(con) self.z = z
(con)
(con) def coordinate(self):
(con) return [self.x, self.y, self.z]
(con)
pointtable = [
(con) [Point1D(x=1), Point1D(x=2), Point1D(x=3), ],
(con) [Point2D(x=1,y=-1), Point2D(x=2,y=-2), Point2D(x=3,y=-3), ],
(con) [Point3D(x=1,y=-1,z=10), Point3D(x=2,y=-2,z=20), Point3D(x=3,y=-3,z=30),],
(con)]
for pointrow in pointtable:
(con) for point in pointrow:
(con) print(f"{point.coordinate()} is ", end="")
(con) match point:
(con) case Point(x= 3, y=-3):
(con) print('pattern 1')
(con) case Point(x= _, z= _):
(con) print('pattern 2')
(con) case Point(y=_):
(con) print('pattern 3')
(con) case Point(x = 1, y =-1|-2):
(con) print('pattern 4')
(con) case Point(x = 1):
(con) print('pattern 5')
(con) case Point():
(con) print('pattern 6')
(con) case _:
(con) print('not matched')
(con)
(out)[1] is pattern 5
(out)[2] is pattern 6
(out)[3] is pattern 6
(out)[1, -1] is pattern 3
(out)[2, -2] is pattern 3
(out)[3, -3] is pattern 1
(out)[1, -1, 10] is pattern 2
(out)[2, -2, 20] is pattern 2
(out)[3, -3, 30] is pattern 1
上のサンプルでは基底クラスPointだけでパターンマッチしているが、case Point1D(x=3)|Point2D(x=3):のように混在させても構わない。
組み込み型のクラスパターンマッチ
組み込み型(bool、bytearray、bytes、dict、float、frozenset、int、list、set、str、tuple)は例外として属性名を指定せず位置引数のような形で値を指定する。キャプチャパターンと組み合わせると、若干わかりにくいかもしれない。
dataset = [1, 1.3, 3, 5.5, "A"]
for data in dataset:
(con) print(f"{data:>3}: ", end="")
(con) match data:
(con) case int(1|2):
(con) print("int 1 or 2")
(con) case int(a): # これは int() as a と等しい
(con) print(f"int({a})")
(con) case float(a): # これは int() as a と等しい
(con) print(f"float({a})")
(con) case _:
(con) print("not number")
(con)
(out) 1: int 1 or 2
(out)1.3: float(1.3)
(out) 3: int(3)
(out)5.5: float(5.5)
(out) A: not number
例外処理
基本構文
0除算など、例外が発生した場合の処理は以下のように指定する。
try:
# 例外が発生しうる処理
except SomeError as e:
# SomeError例外が発生したときの処理
except (CertainError, AnotherError) as e:
# CertainError例外またはAnotherError例外が発生したときの処理
else:
# 例外が発生しなかったときの処理
finally:
# 例外の発生如何に関わらず最後にかならず実行する処理
キャッチした例外を参照しないならas eは不要。
例外を上げる
raise ValueError("エラーメッセージ")
例外を処理中に別の例外が発生することがある。その場合はraise...from...で元となった例外を示すことができる。
raise newexception from originalexceptio
トレースバックを取得
import traceback
try:
# 例外が発生しうる処理
except:
traceback.print_exc()
例外の種類
よく使われる例外の種類を示す。
| 例外名 | 主な発生する状況 |
|---|---|
| Exception | すべての例外の基底クラス。 |
| AttributeError | 存在しない属性を参照している場合など。タイプミスの可能性あり。 |
| EOFError | データを読み取るときに予期せずEOF(End Of File)となったとき |
| ImportError | モジュールのインポートで問題が発生したとき |
| IndexError | シーケンスのインデックスが範囲外のとき |
| KeyError | マップのキーが存在しないとき |
| KeyboardInterrupt | ユーザーが割り込みを発生させたとき |
| MemoryError | メモリが不足したとき |
| NameError | 存在しない変数を参照したとき |
| OSError | システム関連のエラーが発生した場合に発生 |
| OverflowError | 数値演算でオーバーフローが発生したとき |
| RuntimeError | 実行時エラーが発生したとき |
| StopIteration | イテレータが終了したとき |
| SyntaxError | 構文エラーがあったとき |
| SystemError | インタプリタ内部でエラーがあった場合に発生 |
| TypeError | 型エラーがあったとき |
| ValueError | 値が不正なとき |
独自例外
適当な例外がない場合は独自に例外を作ることもできる。Exceptionクラスを基底クラスにすれば良い。
class OriginalException(Exception):
def __init__(self, message):
super().__init__(message)
型ヒント
Pythonは動的型付け言語と呼ばれ、変数を初期化するときに変数の型を定義しない。実行したときに変数や属性に代入されている型が決定される。
とはいえ実装するときには型を意識しなければならない。コードに変数の型が書かれていないことで、コードを時間を空けて見たときになんの型かわからなくなってしまったり、開発環境の支援(例えばメソッドの候補を表示する)機能が十分に働かないことがある。型ヒントを使用することで、コードの可読性が上がり、開発環境の支援機能がより適切に働くなどのメリットがある。
型ヒントは以下のように記載する。
# 変数の宣言
i:str = "文字列"
# 関数の引数と戻り値
def methodname(arg1:str, arg2:int) -> str:
pass
型の記法
主な型の記法に示す。
| 型 | 記法 | 備考 |
|---|---|---|
| 整数 | int | |
| 小数 | float | |
| 文字列 | str | |
| リスト | list[ X ] (3.9以上) | 古いバージョンではtyping.Listでtypingモジュールのインポートが必要。 |
| タプル | tuple[ X, Y, ... ] (3.9以上) | 古いバージョンではTupleでtypingモジュールのインポートが必要。 |
| 辞書 | dict[ キーの型, バリューの型 ] (3.9以上) | 古いバージョンではtyping.Dictでtypingモジュールのインポートが必要。 |
| シーケンス | Sequence[ X ]MutableSequence[ X ] | インポート必要 from collections.abc import Sequence, MutableSequence |
| コレクション | Collection[ X ] | インポート必要 from collections.abc import Collection |
| イテラブル | Iterable | インポート必要 from collections.abc import Iterable |
| 関数 | Callable[ [引数の型], 戻り値の型 ] | インポート必要 from collections.abc import Callable |
| すべて | Any | インポート必要 from typing import Any |
| 自身 | Self | クラス定義などで使用。インポート必要 from typing import Self |
特殊な記法
| 形式 | 記法 | 意味 |
|---|---|---|
| ユニオン、OR | Union[ X, Y ]X | Y | 指定された型のいずれか |
| オプショナル | Optional[ X ] | 指定された型 または None Optional[X] は Union[ X, None ] と同義 |
| リテラル | Literal[ ... ] (3.8以上) | []の中で指定された値 Literal[ "RED", "BLUE" ] であれば、"RED"または"BLUE"という文字列 |
