Pythonまとめ(6.標準ライブラリその2)
ロギング
はじめに
Pythonではロギング機能をもつloggingライブラリが標準で提供されている。loggingライブラリを使うにあたり基本となる用語とログ処理の流れを示す。
| 用語 | 説明 | サンプル |
|---|---|---|
| ロガー | ログ記録の設定をとりまとめ実行するクラス | logger = logging.getLogger( "FileReader" ) |
| ログレコード | ログが発生するごとに作成されるログイベント | |
| ハンドラ | ログレコードの処理を行うクラス | logger.addHandler( handler ) |
| フォーマッタ | ログレコードを指定の書式に整形するクラス | |
| フィルタ | 処理するログレコードを選別するクラスまたは関数 | logger.addFilter(lambda x: x.getMessage().startswith("!")) |
| ログレベル | ログの重大度を表すもの。実態は整数値 | `logging.INFO |
ログを記録するには以下の手順に従う。なお説明のために順序を問わない手順やオプションの手順も含まれている。
- ロガーを取得する
- ロガーを設定する
- ロガーのログレベルを設定する
- ロガーのフィルタを設定する
- ハンドラを生成・設定する
- フォーマッタを作成し、ハンドラにアタッチする
- ハンドラのフィルタを作成し、ハンドラにアタッチする
- ハンドラのログレベルを設定する
- ロガーにハンドラをアタッチする
- ログを記録する
ロガー
Pythonのloggingには名前空間という考えがある。名前はA.B.Cのようにドット区切りの階層構造が利用できる。ログを取得するロガーを取得するときは名前を指定して取得する。名前が同じであれば、別のPythonファイルであっても同じロガーが返される。(もちろん同じPythonインタプリタ上である必要はある)
あなたが画像処理を行うプログラムを書いており、その中でI/O部分の処理に関するログを記録したい。その場合には以下のように「Imaging.IO」という名前のImagingを親とするIO用の子ロガーを取得できる。Imaging.IOという名前のロガーを取得する方法は2通りある。
logger1 = logging.getLogger( "Imaging.IO" )
logger2 = logging.getLogger( "Imaging" ).getChild( "IO" )
logger1 is logger2
(out)True
この階層構造の特徴を使用して、複数ファイルにまたがるプログラムでは、全体で共通な「基本となるロガー名」をmainに相当するプログラムが初期化し、各ファイルではそのロガーを使用すればよい。
import imagingio # imagingioをインポート
def main():
logger = logging.getLogger( "Imaging" )
# "Imaging"というロガーの初期設定をここで実施
if __name__ == "__main__":
main()
logger = logging.getLogger( "Imaging" ) # このロガーはimaging-main.pyで初期設定したロガーと同一
logger.getChild( "IO" ) # 子ロガーを取得し、another.py独自のログ設定を加えることもできる
ロガーにはログを記録するメソッドがログレベルごとに用意されている。警告に相当するログを記録する例を示す。
logger1.warning("Warning!")
(out)Warning!
ハンドラ
ロガーに記録されたログをどのように処理するかはハンドラが決める。この処理には、画面(標準出力)に表示する、ファイルに記録する、シスログに送信するなどが考えられるが、一般的なハンドラがライブラリに用意されている。
ハンドラはロガーに登録して使用する。1つのロガーにたいして複数のハンドラを登録することができるため、メッセージを画面に出力した上でファイルにも記録するという処理も行える。ここでは標準出力に表示するハンドラをロガーに登録するサンプルを示す。他のハンドラは後述する。
logger1 = logging.getLogger("log")
stdouthandler = logging.StreamHandler( stream=sys.stdout ) # ストリームに出力するハンドラStreamHandlerで出力先ストリームは標準出力を指定
logger1.addHandler(stdouthandler) # ハンドラを登録フォーマッタ
記録されたログがどのように出力されるかはフォーマッタで指定する。例えば「時間 ロガー名 メッセージ」のような書式であったり「時間 ログレベル メッセージ」のような書式が指定できる。フォーマッタはハンドラに設定する。ここではフォーマッタを作成し、ハンドラに設定する部分のみを示し、具体的な設定内容については後述する。
formatter = logging.Formatter(fmt="{asctime}:{name}:{module}.{funcName}.{lineno}:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
stdouthandler.setFormatter(formatter)
(out)# 2023-07-23 02:28:26:log.io.file:WARNING:test3-3 のようなフォーマットになる
フィルタ
ロガーに記録されたログのうち、条件を満たしたログだけを処理するようにフィルタで設定できる。フィルタはロガーとハンドラの両方に設定できる。ここではハンドラにフィルタを設定するサンプルのみを示す。
stdouthandler.addFilter(lambda x:x.getMessage().startswith("test")) # testで始まるログメッセージのみを記録するフィルタ
ハンドラーとロガーの両方にフィルタがある場合は、まずロガーのフィルタが評価される。ロガーのフィルタを通過したログは順に各ハンドラに渡される。各ハンドラでフィルタをさらに適用し、フィルタごとに処理をするかどうか決定する。複数のフィルタが設定されている場合は、すべてがTrueとなるログだけが処理される
ルートロガー
ちょっとしたプログラムならlogging自体をロガーとして使うことができる。loggingはルートロガーである。デフォルトではWARN以上のログが標準エラー出力に表示される。
logging.warning("Warning!")
(out)WARNING:root:Warning!
ロガーを使ってみる
何も設定しなかった場合、WARN以上のログが標準エラー出力にそのまま表示される。
import logging
import sys
logger1 = logging.getLogger("log")
logger1.warning("test1-1")
(out)test1-1
ハンドラの設定
StreamHandlerを設定してみる。StreamHandlerは何も設定しなかった場合、WARN以上のログがストリームにそのまま出力される。
import logging
import sys
logger1 = logging.getLogger("log")
shandler = logging.StreamHandler( stream=sys.stdout )
logger1.addHandler(shandler)
logger1.warning("test2-1")
(out)test2-1
結果だけでは最初と違いがないように見えるが、標準エラー出力と標準出力という点で変わっている。
フォーマッタの設定
ハンドラにフォーマッタを設定することで、ログのフォーマットが変わる。
import logging
import sys
shandler = logging.StreamHandler( stream=sys.stdout )
formatter = logging.Formatter(fmt="{asctime}:Handler1:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
shandler.setFormatter(formatter)
logger1 = logging.getLogger("log")
logger1.addHandler(shandler)
logger1.warning("test3-1")
(out)2023-07-23 02:42:20:Handler1:test3-1
フィルタの設定
ハンドラまたはロガーにフィルタを設定することで、処理するログを選択できる。この例ではハンドラに設定する。
import logging
import sys
shandler = logging.StreamHandler( stream=sys.stdout )
formatter = logging.Formatter(fmt="{asctime}:Handler1:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
shandler.setFormatter(formatter)
shandler.addFilter(lambda x:x.getMessage().startswith("test")) # testで始まるログだけを記録
logger1 = logging.getLogger("log")
logger1.addHandler(shandler)
logger1.warning("test4-1")
(out)2023-07-23 02:45:17:Handler1:test4-1
logger1.warning("TEST4-2")
小文字のtestで始まらない「TEST4-2」は画面に表示されない。
ログレベルの設定
初期設定ではWARN以上だけが表示される。setLevelで取得するログレベルを選択できる。ログレベルの設定はロガーとハンドラの両方に存在する。
import logging
import sys
logger1 = logging.getLogger("log")
shandler = logging.StreamHandler( stream=sys.stdout )
formatter = logging.Formatter(fmt="{asctime}:Handler1:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
shandler.setFormatter(formatter)
shandler.addFilter(lambda x:x.getMessage().startswith("test"))
logger1.addHandler(shandler)
logger1.info("test5-1")
shandler.setLevel(logging.INFO)
logger1.info("test5-2")
logger1.setLevel(logging.INFO)
logger1.info("test5-3")
(out)2023-07-23 02:47:49:Handler1:test5-3
この例ではログレベルの設定を変えながらINFOのレベルのログを3回記録しているが、処理されるのはtest5-3だけである。test5-1の時点ではロガーとハンドラの両方がWARN以上のログレベル設定であるため処理されず、test5-2ではハンドラはINFO以上であるがロガーがWARN以上であるため処理されない。
プロパゲート
親子関係にあるlogger1とlogger2それぞれにハンドラを設定する。子ロガーであるlogger2でログを発行すると、そのlogger1とlogger2の両方でログが記録される。この子ロガーのログが親ロガーに伝わる(伝搬する)動作をプロパゲートという。
import logging
import sys
# 親ロガー「log」の設定
logger1 = logging.getLogger("log")
logger1.setLevel(logging.INFO) # ログレベルINFO
# ロガーlogに適用するハンドラの設定
shandler1 = logging.StreamHandler( stream=sys.stdout )
formatter1 = logging.Formatter(fmt="Handler1:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
shandler1.setFormatter(formatter1)
shandler1.addFilter(lambda x:x.getMessage().startswith("test")) # フィルタあり
shandler1.setLevel(logging.INFO) # ログレベルINFO
logger1.addHandler(shandler1)
# 子ロガー「log.io」の設定
logger2 = logging.getLogger("log.io") # logging.getLogger("log").getChild("io")でも同じ
logger2.setLevel(logging.DEBUG) # ログレベルDEBUG
# ロガーlog.ioに適用するハンドラの設定 1つ目
shandler2 = logging.StreamHandler( stream=sys.stdout )
formatter2 = logging.Formatter(fmt="Handler2:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
shandler2.setFormatter(formatter2)
shandler2.setLevel(logging.INFO) # ログレベルINFO
logger2.addHandler(shandler2)
# ロガーlog.ioに適用するハンドラの設定 2つ目
shandler3 = logging.StreamHandler( stream=sys.stdout )
formatter3 = logging.Formatter(fmt="Handler3:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S")
shandler3.setFormatter(formatter3)
shandler3.setLevel(logging.DEBUG) # ログレベルDEBUG
logger2.addHandler(shandler3)
print('TEST1-1')
(out)TEST1-1
logger1.info("test1 1-info")
(out)Handler1:test1 1-info
print('TEST1-2')
(out)TEST1-2
logger2.info("test1 2-info")
(out)Handler2:test1 2-info
(out)Handler3:test1 2-info
(out)Handler1:test1 2-info
print('TEST1-3')
(out)TEST1-3
logger2.info("TEST1 3-info")
(out)Handler2:TEST1 3-info
(out)Handler3:TEST1 3-info
print('TEST2-1')
(out)TEST2-1
logger1.debug("test2 1-debug")
print('TEST2-2')
(out)TEST2-2
logger2.debug("test2 2-debug")
(out)Handler3:test2 2-debug
| テストケース | 結果 | 説明 |
|---|---|---|
| TEST1-1 | Handler1:test1 1-info | logger1でINFOログを記録。 logger1で記録されたメッセージは子ロガーであるlogger2には流れない。 |
| TEST1-2 | Handler2:test1 2-info Handler3:test1 2-info Handler1:test1 2-info | logger2でINFOログを記録。 logger2のすべてのハンドラで処理されたあとで、親ロガーであるlogger1のハンドラへ渡されている。 |
| TEST1-3 | Handler2:TEST1 3-info Handler3:TEST1 3-info | logger2で「TEST」から始まるINFOログを記録。 logger2のすべてのハンドラで処理されたあとで、親ロガーであるlogger1へ渡され、logger1のすべてのハンドラで処理される。 ただしshandler1のフィルタ設定により記録されていない。 |
| TEST2-1 | (出力なし) | logger1でDEBUGログを記録。 logger1のログレベル設定がINFOであるため記録されていない。 |
| TEST2-2 | Handler3:test2 2-debug | logger2でDEBUGログを記録。 logger2にはハンドラが2つあるが、shandler2はログレベル設定がINFOであるため記録されていない。 その後logger1にも渡されているが、logger1のログレベル設定がINFOであるためshandler1は呼び出されない。 |
このプロパゲートを利用してログを記録すると良い。
- 自分で大元となるロガー名を決める
- ルートロガー(logging)は使わない
- mainで大元のロガーを初期化する
- 他のファイルは子ロガーを取得してログを取る。カスタマイズしたいときは子ロガーをカスタマイズする。
- 子ロガーでカスタマイズすることで親ロガーを汚さない
なお、プロパゲートは設定で無効にすることもできる。
補足
ログレベルと発行メソッドの補足
ログにはレベルがあり、各ログレベルに対応する記録メソッドが標準で提供されている。
| レベル | 数値 | 発行メソッド |
|---|---|---|
| CRITICAL | 50 | Logger.critical(msg, *args, **kwargs) |
| ERROR | 40 | Logger.error(msg, *args, **kwargs)Logger.exeption(msg) ※except句などで使用 |
| WARNING | 30 | Logger.warning(msg, *args, **kwargs) |
| INFO | 20 | Logger.info(msg, *args, **kwargs) |
| DEBUG | 10 | Logger.debug(msg, *args, **kwargs) |
| NOTSET | 0 | Logger.log(0, msg, *args, **kwargs) ※logメソッドはログレベルを指定して記録できる |
表に記載のない数字(たとえば15)も使用できる。
フィルタの補足
フィルタは結果がTrue(ノンゼロ)の場合のみ記録される。たとえば特定の文字から始まる場合のみ記録するフィルターは以下のように作成できる。
logger.addFilter(lambda x: x.getMessage().startswith("!!!!"))
logger.warning("!!!") # 記録されない
logger.warning("!!!!")
(out)!!!!
ラムダ式の引数xにはLogRecordオブジェクトが渡される。LogRecordオブジェクトはログが記録するたびにLoggerが生成するオブジェクトであり、メッセージに関わるイベントの情報すべてを含んでいる。
なお、Python3.2より前はFilterクラスを作成したり、filterメソッドを持つクラスを使う必要があったが、現在はfilterとして渡されたオブジェクトが、Filterクラスでなく、filterメソッドを持つクラスでもない場合は、callableとして処理されるようになり、上のようにラムダ式が使用できるようになった。旧スタイルでの実装例を示す。
import logging
class StartsWithFilter(logging.Filter): # logging.Filterを継承
(con) def __init__(self, keyword):
(con) super().__init__()
(con) self.keyword = keyword
(con)
(con) def filter(self, record): # filterメソッドを実装
(con) return record.getMessage().startswith(self.keyword)
(con)
logger = logging.getLogger("TEST")
logger.addFilter(StartsWithFilter("!!"))
logger.warning("!") # 表示されない
logger.warning("!!")
(out)!!
logger.warning("!!!")
(out)!!!
logger.addFilter(StartsWithFilter("!!!")) # フィルターを追加
logger.warning("!") # 表示されない
logger.warning("!!") # 表示されない
logger.warning("!!!")
(out)!!!
ログの書式の補足
フォーマットの指定スタイルにはprintfスタイル(%)、str.formatスタイル({)、string.Templateスタイル($)の3つがあり、後方互換性のためデフォルトは%になっている。そのためフォーマット文字列の書式を使うにはstyle引数に'{'を指定する。また{asctime}の時刻の書式をdatefmt引数で指定できる。
logger.setFormatter( logging.Formatter(fmt="{asctime}:{message}", style='{', datefmt="%Y-%m-%d %H:%M:%S") )
ログの書式で使用できる主要なものを示す。
| 属性名 | 意味 |
|---|---|
| asctime | ログレコードの作成日時(人間が読める形式) |
| filename | ログを呼び出したファイル名 |
| funcName | ログを呼び出した関数名 |
| levelname | ログレベルの名前(DEBUG, INFOなど) |
| lineno | ログを呼び出したソースコードの行番号 |
| message | ログメッセージ本文 |
| module | ログを呼び出したモジュール名 |
| name | ロガーの名前 |
定義されていない属性も指定できるが、その情報をログ記録時に渡す必要がある。渡されない場合に例外が発生するため実装に注意が必要となってしまう。理由がないなら使用しないほうが良いだろう。
logger.setFormatter( logging.Formatter( fmt=r"{asctime} [{user}] %{message}",style='{') ) # 対応していないuserがフォーマットに含まれている
logger.warning("warn", extra={"user":"Inoue"}) # extraでuser情報を渡す
(out)2023-07-18 02:02:50,763 [Inoue] warn
logger.warning("warn") # user情報を渡さずにログ発行
(out)--- Logging error ---
(out)(省略)
(out)KeyError: 'user'
(out)During handling of the above exception, another exception occurred:
(out)ValueError: Formatting field not found in record: 'user'
(out)(省略)
ハンドラ
以下のハンドラがライブラリに用意されている。基本的にはこのハンドラを利用する。ハンドラによってインポートするモジュールが違う点に注意。
| ハンドラ名 | 動作 | import |
|---|---|---|
| StreamHandler | ストリームに出力する | logging |
| FileHandler | ファイルに出力する | logging |
| RotatingFileHandler | ファイルに出力する。ファイルはサイズやバックアップ数に応じてローテーションする。 | logging.handlers |
| TimedRotatingFileHandler | ファイルに出力する。ファイルは時間間隔やバックアップ数に応じてローテーションする。 | logging.handlers |
| SocketHandler | TCPで送信する | logging.handlers |
| DatagramHandler | UDPで送信する | logging.handlers |
| SMTPHandler | メールで送信する | logging.handlers |
| SysLogHandler | syslogに送信する | logging.handlers |
| NTEventLogHandler | Windowsのイベントログに送信する | logging.handlers |
| HTTPHandler | HTTP POSTリクエストとして送信する | logging.handlers |
| NullHandler | 何もしない(無視する) | logging |
個人用テンプレート
個人的によく使うlogging設定
import logging
import logging.handlers
import os
logger = logging.getLogger("log")
handler = logging.handlers.RotatingFileHandler(filename="logfile.log", maxBytes=1000000, backupCount=3, encoding='utf-8')
handler.setFormatter( logging.Formatter(fmt="{asctime}.{msecs:03.0f} {name}:{levelname} {message}", style='{', datefmt="%Y-%m-%d %H:%M:%S") )
handler.setLevel(logging.INFO)
logger.setLevel(logging.DEBUG)
logger.addHandler(handler)
logger = logger.getChild( os.path.basename(__file__) )
ロギング設定ファイル
ある程度のプログラム規模になるとログの挙動は設定ファイルなどで定義できることが望ましい。通常はWARNだけを記録しておくが、想定外の異常が発生したらDEBUG記録を有効化することで、異常の原因分析がプログラム自体をいじることなく柔軟にできる。logging.configモジュールでこれを実現できる。
logging.configには辞書形式で設定をインポートする機能がある。なのでそれに対応したYAML形式等で設定をファイルに記録し、それをインポートすれば良い。設定ファイルを読み込むサンプルを示す。
version: 1
formatters:
normal:
format: "{asctime}.{msecs:03.0f} {name}:{levelname} {message}"
style: "{"
datefmt: "%Y-%m-%d %H:%M:%S"
handlers:
console:
class : logging.StreamHandler
formatter: normal
level : INFO
stream : ext://sys.stdout
file:
class : logging.handlers.RotatingFileHandler
formatter: normal
level: INFO
filename: logfile.log
maxBytes: 1024
backupCount: 3
loggers:
log:
handlers: [console, file]
level: INFO
import logging
import logging.handlers
import logging.config
import yaml
with open('logconfig.yaml') as file:
(con) config = yaml.safe_load(file.read())
(con)
logging.config.dictConfig(config) # 辞書を元にロギングを設定
logger = logging.getLogger("log")
logger.warning("警告")
ロギング設定ファイルの書き方
上のサンプルを見ればだいたい分かるが、主にはformatters、handlers、filters、loggersのセクションがあり、各セクションの中で必要な定義を行う。基本的には以下の通りとなる。
TYPE: # 設定するものの種類(主にformattersかhandlersかfiltersかloggers)
NAME1: # 設定するものの名前(変数名と思えば良い)
key1 : value1 # NAME1の設定1
key2 : value2 # NAME1の設定2
NAME2: # 設定するものの名前(変数名と思えば良い)
key1 : value1 # NAME2の設定1
key2 : value2 # NAME2の設定2
以下であればnormalという名前のフォーマッタを定義している。normalというフォーマッタのフォーマットは「{asctime}.{msecs:03.0f} {name}:{levelname} {message}」、フォーマット文字の書式は「{」という具合だ。
formatters:
normal:
format: "{asctime}.{msecs:03.0f} {name}:{levelname} {message}"
style: "{"
datefmt: "%Y-%m-%d %H:%M:%S"
こうすると、ハンドラを設定するときに上で定義した「normal」フォーマッタを参照できる。
handlers:
console: # ハンドラ名
class : logging.StreamHandler # ハンドラのクラス名
formatter: normal # ハンドラが使用するフォーマッタ
level : INFO # ハンドラのログレベル
stream : ext://sys.stdout # ハンドラ依存の個別設定は「__init__メソッドのキーワード引数:設定値」の書式で書く
そして最後にロガーを設定する。ここでも上で作成したハンドラ名を指定する。ハンドラ名、フォーマッタ名は設定ファイル内で統一されていればなんでも良いが、ロガー名はロガーの名前空間を表すものであため、実際に使うものにする必要がある。
loggers:
log.io.a: # ロガー名( logging.getLogger()で指定する名前 )
handlers: [console, file] # ハンドラ名のリスト
level: INFO # ハンドラのログレベル
なお、将来の互換性のためにversionが必須となっているが、2023年現在で指定できるバージョンは1だけだ。
すべてのスキーマはhttps://docs.python.org/ja/3/library/logging.config.html#logging-config-dictschemaにある。
fileConfig()
設定をファイルから直接読み込むfileConfigメソッドもある。ただし、dictConfigのほうが新しいAPIであり推奨されている。
ipaddress
ipaddressはIPアドレスに関する操作やヘルパー関数が含まれる標準ライブラリである。ここではIPv4に重点を置いて説明する。
主要クラス
ipaddressライブラリにはIPアドレス、ネットワーク、ネットワークインタフェースに対応するクラスがある。
| 種類 | 特徴 | 対応する値の例 | 対応しない値の例 |
|---|---|---|---|
| IPアドレス ipaddress.IPv4Address ipaddress.IPv6Address | ・ネットワークアドレス長を持たない | 192.168.1.1 192.168.0.0 | ・ネットワークアドレス長を含む値 192.168.1.0/24 192.168.1.1/32 |
| ネットワークアドレス ipaddress.IPv4Network ipaddress.IPv6Network | ・ネットワークアドレス長を持つ ・ホストビットが0である | 192.168.0.0 192.168.1.0/24 | ・ホストビットが0でない 192.168.1.1/24 |
| ネットワークインタフェース ipaddress.IPv4Interface ipaddress.IPv6Interface | ・ネットワークアドレス長を持つ | 192.168.1.10 192.168.1.0/24 192.168.1.1/24 | 特になし |
IPv4Address
IPアドレスを表すクラスとしてipaddress.IPv4Addressとipaddress.IPv6Addressがある。それぞれのクラスを直接作成しても良いが、ipaddress.ip_addressというIPv4/IPv6を区別しなくても良いメソッドもある。
import ipaddress
ipaddress.IPv4Address("192.168.1.1")
(out)IPv4Address('192.168.1.1')
ipaddress.ip_address("192.168.1.1")
(out)IPv4Address('192.168.1.1')
IPアドレスクラスはネットワークに関する情報を持たない。そのためCIDR表記のアドレスを指定するとエラーになる。
ipaddress.IPv4Address("192.168.1.0/24")
(out)Exception has occurred: AddressValueError
(out)Unexpected '/' in '192.168.1.0/24'
IPv4アドレスは以下の属性を持つ。
| reverse_pointer | 逆引きのレコード名。1.1.168.192.in-addr.arpa など |
| is_global | IPアドレスがグローバルIPアドレスの場合True |
| is_link_local | IPアドレスがリンクローカルアドレスの場合True |
| is_loopback | IPアドレスがループバックアドレスの場合True |
| is_multicast | IPアドレスがマルチキャストアドレスの場合True |
| is_private | IPアドレスがプライベートIPアドレスの場合True |
| is_reserved | IPアドレスがIETFで予約されているアドレスの場合True |
| is_unspecified | IPアドレスがRFCで未定義の場合True |
IPv4Network
ネットワークを表すクラスとしてipaddress.IPv4Networkとipaddress.IPv6Networkがある。それぞれのクラスを直接作成しても良いが、ipaddress.ip_networkというIPv4/IPv6を区別しなくても良いメソッドもある。ネットワークアドレス長はCIDR表記かマスクで指定する。指定されなかった場合は/32とみなされる。
# 以下はすべておなじになる
ipaddress.ip_network("192.168.2.0/24")
ipaddress.ip_network("192.168.2.0/255.255.255.0")
ipaddress.ip_network("192.168.2.0/0.0.0.255")
ipaddress.ip_network(("192.168.2.0", 24))
ipaddress.ip_network(("192.168.2.0", "255.255.255.0"))
ipaddress.ip_network(("192.168.2.0", "0.0.0.255"))
# intでもOK
ipaddress.ip_network((3232236032, 24))
ネットワークを表すクラスのため、ホストアドレス部は0でなければならない。0でない場合ValueErrorが発生する。
ip1 = ipaddress.ip_network("192.168.2.1/24")
(out)Exception has occurred: ValueError
(out)192.168.2.1/24 has host bits set
ネットワークアドレスに関する属性が利用できる。
| with_hostmask | ホストマスク、ワイルドカードマスク付きの表記 | 192.168.1.1/0.0.0.255 |
| with_netmask | ネットマスク付きの表記 | 192.168.1.1/255.255.255.0 |
| with_prefixlen | CIDR表記 | 192.168.1.1/24 |
| network_address | ネットワークアドレス | 192.168.1.0 |
| broadcast_address | ブロードキャストアドレス | 192.168.1.255 |
| netmask | サブネットマスク | 255.255.255.0 |
| prefixlen | プレフィックス長 | 24 |
| reverse_pointer | 逆引きするときのレコード名 | 0/24.1.168.192.in-addr.arpa |
ネットワーク演算
サブネットやスーパーネットなどを取得するメソッドが提供されている。
| メソッド名 | 引数 | 戻り値 | 説明 |
|---|---|---|---|
| subnets | new_prefix:新しいサブネット長の指定 prefixlen_diff:相対的な新しいサブネット長の指定 | 指定のサブネット長に分割したサブネットのgenerator | 現在のネットワークを指定のサブネット長に分割する。 指定がない場合prefixlen_diff=1の動作になる。 結果は複数のサブネットになるため、generatorで得られる。 |
| supernet | new_prefix:新しいサブネット長の指定 prefixlen_diff:相対的な新しいサブネット長の指定 | 指定のサブネット長のスーパーネット | 指定のサブネット長のスーパーネットを取得する。 指定がない場合prefixlen_diff=1の動作になる。 |
| address_exclude | 除外するサブネット | 指定のサブネットを除外したサブネットのgenerator | 現在のネットワークから指定のサブネットを除外する |
subnets
ip1 = ipaddress.ip_network("192.168.2.0/24")
list(ip1.subnets())
(out)[IPv4Network('192.168.2.0/25'), IPv4Network('192.168.2.128/25')]
list(ip1.subnets(prefixlen_diff=2))
(out)[IPv4Network('192.168.2.0/26'), IPv4Network('192.168.2.64/26'), IPv4Network('192.168.2.128/26'), IPv4Network('192.168.2.192/26')]
list(ip1.subnets(new_prefix=27))
(out)[IPv4Network('192.168.2.0/27'), IPv4Network('192.168.2.32/27'), IPv4Network('192.168.2.64/27'), IPv4Network('192.168.2.96/27'), IPv4Network('192.168.2.128/27'), IPv4Network('192.168.2.160/27'), IPv4Network('192.168.2.192/27'), IPv4Network('192.168.2.224/27')]
supernet
ip1 = ipaddress.ip_network("192.168.2.0/24")
ip1.supernet()
(out)IPv4Network('192.168.2.0/23')
ip1.supernet(prefixlen_diff=2)
(out)IPv4Network('192.168.0.0/22')
ip1.supernet(new_prefix=21)
(out)IPv4Network('192.168.0.0/21')
address_exclude
net1 = ipaddress.IPv4Network('192.168.1.0/24')
net2 = ipaddress.IPv4Network('192.168.0.0/16')
exclude=net2.address_exclude(net1)
sorted(list(exclude))
(out)[IPv4Network('192.168.0.0/24'), IPv4Network('192.168.2.0/23'), IPv4Network('192.168.4.0/22'), IPv4Network('192.168.8.0/21'), IPv4Network('192.168.16.0/20'), IPv4Network('192.168.32.0/19'), IPv4Network('192.168.64.0/18'), IPv4Network('192.168.128.0/17')]
比較演算
ネットワークがあるネットワークのサブネット/スーパーネットか判定するメソッドが用意されている。これで包含判定が行える。このメソッドは等しくてもTrueとなる。
| メソッド名 | 引数 | 戻り値 |
|---|---|---|
| subnet_of | other:比較対象のネットワーク | ネットワークが、比較対象のネットワークのサブネットまたは同じネットワークならTrue |
| supernet_of | other:比較対象のネットワーク | ネットワークが、比較対象のネットワークのスーパーネットまたは同じネットワークならTrue |
| overlaps | other:比較対象のネットワーク | ネットワークが、比較対象のネットワークと重なっている部分があるならTrue ( A.subnet_of(B) または A.supernet_of(B) が成り立つなら A.overlaps(B) はTrue) |
net1 = ipaddress.IPv4Network("192.168.1.0/24")
net2 = ipaddress.IPv4Network("192.168.2.0/24")
net3 = ipaddress.IPv4Network("192.168.0.0/16")
net4 = ipaddress.IPv4Network("192.0.0.0/8")
net1.subnet_of(net1)
(out)True
net1.subnet_of(net2)
(out)False
net1.subnet_of(net3)
(out)True
net3.supernet_of(net1)
(out)True
net3.supernet_of(net2)
(out)True
net3.supernet_of(net3)
(out)True
net3.supernet_of(net4)
(out)False
サブネットかスーパーネットかを問わず、重なっている部分があるならTrueとなるoverlapsメソッドも用意されている。
net1 = ipaddress.IPv4Network('192.168.1.0/24')
net2 = ipaddress.IPv4Network('192.168.2.0/24')
net3 = ipaddress.IPv4Network('192.168.0.0/16')
net1.overlaps(net2)
(out)False
net1.overlaps(net3)
(out)True
IPv4Interface
インタフェースを表すクラスとしてipaddress.IPv4Interfaceとipaddress.IPv6Interfaceがある。それぞれのクラスを直接作成しても良いが、ipaddress.ip_interfaceというIPv4/IPv6を区別しなくても良いメソッドもある。ネットワークアドレス長はCIDR表記かマスクで指定する。指定されなかった場合は/32とみなされる。
# 以下はすべておなじになる
ipaddress.ip_interface("192.168.2.1/24")
ipaddress.ip_interface("192.168.2.1/255.255.255.0")
ipaddress.ip_interface("192.168.2.1/0.0.0.255")
ipaddress.ip_interface(("192.168.2.1", 24))
ipaddress.ip_interface(("192.168.2.1", "255.255.255.0"))
ipaddress.ip_interface(("192.168.2.1", "0.0.0.255"))
# intでもOK
ipaddress.ip_interface((3232236033, 24))
IPv4InterfaceはIPv4AddressとIPv4Networkの両方の特性を併せ持つクラスである。ip属性とnetwork属性で両方のオブジェクトを取得できる。
| ip | ネットワーク情報を持たないAddressの情報 | <class 'ipaddress.IPv4Address'> |
| network | インタフェースが属するNetworkの情報 | <class 'ipaddress.IPv4Network'> |
| with_prefixlen | CIDR表記 | 192.168.1.1/24 |
| with_netmask | ネットマスク付きの表記 | 192.168.1.1/255.255.255.0 |
| with_hostmask | ホストマスク、ワイルドカードマスク付きの表記 | 192.168.1.1/0.0.0.255 |
| reverse_pointer | 逆引きするときのレコード名 | 10/24.1.168.192.in-addr.arpa |
ipi = ipaddress.IPv4Interface('192.168.1.10/24')
type(ipi.ip)
(out)<class 'ipaddress.IPv4Address'>
type(ipi.network)
(out)<class 'ipaddress.IPv4Network'>
その他の演算・メソッド
IPアドレスとネットワークの包含判定
IPアドレスがネットワークに含まれているか確認するにはin演算子を使う。
ipa = ipaddress.IPv4Address('192.168.1.10')
net1 = ipaddress.IPv4Network('192.168.1.0/24')
net2 = ipaddress.IPv4Network('192.168.2.0/24')
ipa in net1
(out)True
ipa in net2
(out)False
順序判定(大小判定)
同じクラスであれば不等号で大小比較が行える。そのためsortも特に意識することなく行える。
ip1, ip2, ip3, ip4 = list(map( ipaddress.IPv4Address, ("192.168.1.1","192.168.2.1","192.168.2.5","192.169.1.0") ))
(out)9.1.0/24") ))
ni1, ni2, ni3, ni4 = list(map( ipaddress.IPv4Interface, ("192.168.1.1/24","192.168.2.1/24","192.168.2.5/24","192.169.1.0/24") ))
net1,net2,net3,net4 = list(map( ipaddress.IPv4Network, ("192.168.1.0/24", "192.168.2.0/24", "192.168.0.0/16", "192.0.0.0/8") ))
ip1 < ip1
(out)False
ip1 < ip2
(out)True
ip1 < ip3
(out)True
ip1 < ip4
(out)True
ni1 < ni1
(out)False
ni1 < ni2
(out)True
ni1 < ni3
(out)True
ni1 < ni4
(out)True
net1 < net1
(out)False
net1 < net2
(out)True
net1 < net3
(out)False
net1 < net4
(out)False
IPアドレスとネットワークは種類が違うため通常は順序判定の対象となるものではないが、それでもソートしたい場合などはipaddress.get_mixed_type_keyメソッドをソートのキーとして利用できる。
アドレス集約
ipaddress.collapse_addressメソッドで連続するネットワークを集約することができる。戻り値はgeneratorである。
net1 = ipaddress.IPv4Network("192.168.0.0/24")
net2 = ipaddress.IPv4Network("192.168.1.0/24")
net3 = ipaddress.IPv4Network("192.168.4.0/24")
net4 = ipaddress.IPv4Network("192.168.0.0/16")
list1 = [net1,net2]
list2 = [net1,net2,net3]
list3 = [net1,net4]
list( ipaddress.collapse_addresses(list1) )
(out)[IPv4Network('192.168.0.0/23')]
list( ipaddress.collapse_addresses(list2) )
(out)[IPv4Network('192.168.0.0/23'), IPv4Network('192.168.4.0/24')]
list( ipaddress.collapse_addresses(list3) )
(out)[IPv4Network('192.168.0.0/16')]
ネットワークの算出
先頭と末尾のアドレスから、そのアドレス範囲をカバーできるネットワークアドレスのリストを求める。戻り値はgeneratorである。
ipa1 = ipaddress.IPv4Address("192.168.10.0")
ipa2 = ipaddress.IPv4Address("192.168.10.16")
ipa3 = ipaddress.IPv4Address("192.168.10.63")
ipa4 = ipaddress.IPv4Address("192.168.10.64")
list( ipaddress.summarize_address_range(ipa1,ipa2) )
(out)[IPv4Network('192.168.10.0/28'), IPv4Network('192.168.10.16/32')]
list( ipaddress.summarize_address_range(ipa1,ipa3) )
(out)[IPv4Network('192.168.10.0/26')]
list( ipaddress.summarize_address_range(ipa1,ipa4) )
(out)[IPv4Network('192.168.10.0/26'), IPv4Network('192.168.10.64/32')]
DNS(dnspython)
標準機能における名前解決
単純にIPアドレスとFQDNを相互に名前解決できるだけで良いなら、socketライブラリのメソッドを使用できる。
import socket
socket.gethostbyname("example.com")
(out)'93.184.xx.xx'
socket.getfqdn("1.1.1.1")
(out)'one.one.one.one'
それ以上の機能が必要ならdnspythonライブラリを使用する。たとえばMXレコードを取得したり、名前解決するDNSサーバを指定したりだ。
dnspythonの主要クラス
ゾーン、リソースレコード関連
リソースレコードに対応するクラスの概念図を以下に示す。
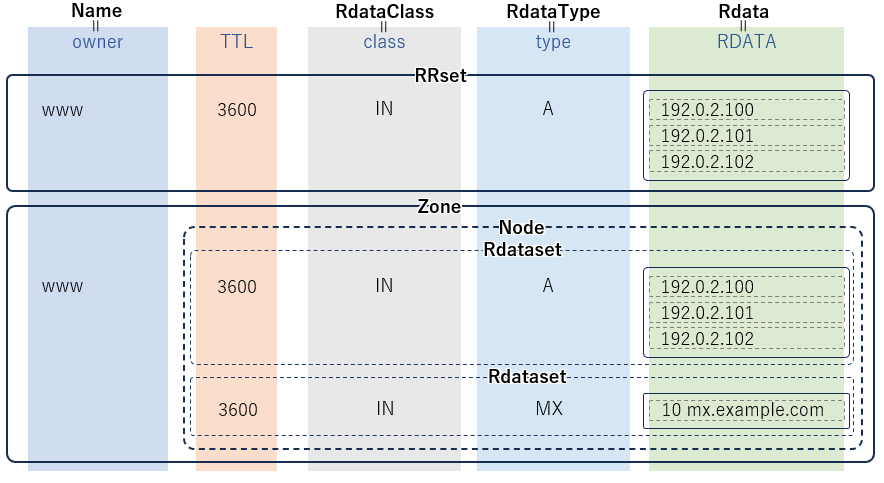
| dns.rrset.RRset | DNSのリソースレコードセット(RRset)に対応するクラス ドメイン名、タイプ、クラスが同じRdataの集合 |
| dns.zone.Zone | 複数のNameとそれに対するNodeをマッピングするクラス |
| dns.node.Node | Rdatasetの集合をあらわすクラス Zoneクラスにおいて1つのNameに対応する複数のクラス、タイプのRdatasetをまとめて管理するために使う |
| dns.rdataset.Rdataset | DNSのリソースレコードセットのドメイン名以外に対応するクラス タイプ、クラスが同じRdataの集合 |
| dns.name.Name | DNSのリソースレコードのドメイン名(owner)に対応するクラス |
| dns.rdataclass.RdataClass | DNSのリソースレコードのクラス(class)に対応するクラス |
| dns.rdatatype.RdataType | DNSのリソースレコードのタイプ(type)に対応するクラス |
| dns.rdata.Rdata | DNSのリソースレコードのデータ(RDATA)に対応するクラス |
名前解決関連
名前解決を実行するスタブリゾルバに関するクラスを以下に示す。
| dns.resolver.Resolver | スタブリゾルバ(DNSクライアント) |
| dns.resolver.Answer | スタブリゾルバによる名前解決結果 |
名前解決の実行
名前解決を行うには、Resolverを作成し、resolveメソッドを実行すれば良い。
import dns.resolver
import dns.rdatatype
myresolver = dns.resolver.Resolver()
answer = myresolver.resolve("example.com.",dns.rdatatype.A)
answer.rrset
(out)]>
もし細かい設定が不要ならデフォルトのResolverを使うresolve関数も用意されている。
dns.resolver.resolve("example.com.",dns.rdatatype.A)
ResolverとAnswer
dns.resolver.ResolverはDNSスタブリゾルバである。デフォルトでPOSIXシステムでは /etc/resolv.confファイルの、WindowsシステムではレジストリのDNS設定を使用する。Resolverの属性で動作を変更することができる。ここでは使用するDNSサーバを指定する例を示す。
import dns.resolver
import dns.rdatatype
myresolver = dns.resolver.Resolver()
myresolver.nameservers = ["8.8.8.8", "1.1.1.1"]
name=dns.name.from_text("www.example.com.")
answer = myresolver.resolve(name, dns.rdatatype.A)
resolveメソッドは名前解決を行い、その結果をdns.resolver.Answerで返す。Answerはrrset属性に応答結果のリソースレコードセットを持っているので、応答が見たければAnswer.rrsetを参照する。Answerが持つ主な属性を示す。
| 属性名 | クラス | 説明 |
|---|---|---|
| qname | dns.name.Name | クエリ名 |
| rdclass | int | クエリクラス |
| rdtype | int | クエリタイプ |
| rrset | Optional[dns.rrset.RRset] | 応答のリソースレコードセット |
| expiratopn | float | 応答の有効期限 |
| response | dns.message.QueryMessage | 応答メッセージ |
DNSの応答を読みやすいテキストとして出力したいならrrset属性を文字列にstr()で変換するだけでよい。AnswerのRdataの値だけを取得したい場合はrrsetにシーケンスの方法でアクセスする。また、Answerオブジェクトにシーケンスの方法でアクセスしても、rrset属性へのシーケンスアクセスと同じ結果になる。
import dns.resolver
import dns.rdatatype
import textwrap
resolver = dns.resolver.Resolver()
name=dns.name.from_text("example.com.")
answer = resolver.resolve(name, dns.rdatatype.NS)
str(answer.rrset) # rrsetを文字列に変換
(out)'example.com. 77646 IN NS a.iana-servers.net.\nexample.com. 77646 IN NS b.iana-servers.net.'
str(answer[0]) # Answerオブジェクトにインデックスでアクセス
(out)'a.iana-servers.net.'
str(answer.rrset[1]) # RRsetオブジェクトにインデックスでアクセス
(out)'b.iana-servers.net.'
DNSサーバ、ポートの指定
DNSサーバはdns.nameserver.Nameserverクラスで指定する。dns.nameserver.Nameserverは抽象クラスであり、実際はdns.nameserver.Do53Nameserver(通常のDNSサーバ)やdns.nameserver.DoTNameserver(DNS-over-TCP対応のDNSサーバ)、dns.nameserver.DoHNameserver(DNS-over-HTTPS対応のDNSサーバ)を使用する。なおDoHNameserverを使うにはhttpxモジュールが必要である。
import dns.resolver
import dns.nameserver
myresolver = dns.resolver.Resolver()
ns = dns.nameserver.Do53Nameserver(address="1.1.1.1", port=53)
myresolver.nameservers = [ ns ]
answer = myresolver.resolve( "www.example.com.", "A" )
ns = dns.nameserver.DoTNameserver(address="1.1.1.1", port=853)
myresolver.nameservers = [ ns ]
answer = myresolver.resolve( "example.com.", "MX" )
ns = dns.nameserver.DoHNameserver(url="https://cloudflare-dns.com/dns-query")
myresolver.nameservers = [ ns ]
answer = myresolver.resolve( "example.com.", "SOA" )
なお、DoTやDoHを使用しないdns.nameserver.Do53Nameserverで良ければ、IPアドレスを文字列で直接指定してもよい。nameservers属性に文字列でサーバを指定し、ポート番号をnameserver_portsで指定する。nameserver_portsにポート番号の指定がない場合はportの値が使われる。多くの場合はポートは53(デフォルト値)であるため、ポート番号を指定する必要はほとんどない。
import dns.resolver
myresolver = dns.resolver.Resolver()
myresolver.nameservers = [ "1.1.1.1" ]
# サーバごとのポート番号指定。デフォルトで53なのでこの行は実際は不要
myresolver.nameserver_ports["1.1.1.1"] = 53
# Resolverオブジェクトのデフォルトのポート番号指定。デフォルトで53なのでこの行は実際は不要
myresolver.port = 53
answer = myresolver.resolve( "www.example.com.", "A" )
キャッシュの有効化
Resolverはデフォルトではキャッシュしないが、キャッシュを有効にできる。単純なキャッシュと、キャッシュ数を指定できるLRUキャッシュが用意されている。
import dns.name
import dns.resolver
import time
name = dns.name.from_text("www.example.com.")
resolver = dns.resolver.Resolver()
resolver.cache = dns.resolver.Cache(cleaning_interval=300) # 単純なキャッシュの場合
# resolver.cache = dns.resolver.LRUCache(max_size=100) # LRUキャッシュの場合
answer = resolver.resolve( name, "A" )
str( resolver.cache.get((name,dns.rdatatype.A,dns.rdataclass.IN)).rrset )
(out)'www.example.com. 1332 IN A 93.184.215.14'
time.sleep(3)
answer = resolver.resolve( name, "A" )
f"ヒット:{resolver.cache.hits()} ミス:{resolver.cache.misses()}"
(out)'ヒット:2 ミス:2'
DNSサフィックスの補完
ドメインを補完する機能を有効にできる。たとえばwwwを名前解決しようとしたら、自動でwww.example.com.を名前解決する機能である。DNSサフィックスの補完を有効にするには、補完するサフィックスのリストをsearch属性で指定してから、resolveメソッドでsearch=Trueとした上で、解決する名前を相対名で指定する。
import dns.resolver
import dns.name
resolver = dns.resolver.Resolver()
resolver.search = [ dns.name.from_text("example.com.") ]
name=dns.name.from_text("www", origin=None)
answer = resolver.resolve(name, dns.rdatatype.A, search=True)
str(answer.rrset)
(out)'www.example.com. 3070 IN A 93.184.215.14'
相対名をつくるには、Nameを作成するときにorigin=Noneを指定するか、Name.relativizeメソッドを使う。
import dns.name
dns.name.from_text("www")
(out) # デフォルトは.が補完されてしまう
# origin=Noneを指定
dns.name.from_text("www", origin=None)
(out) # origin=Noneを明示すると補完されない
# relativizeメソッドを使用
base = dns.name.from_text("example.com.")
fqdn = dns.name.from_text("www.example.com.")
fqdn.relativize(base)
(out)
またResolver.use_search_by_defaultをTrueに指定すれば、resolveの引数でsearch=Trueと指定しなくてもDNSサフィックスの補完が有効になる。
import dns.resolver
import dns.name
resolver = dns.resolver.Resolver()
resolver.search = [ dns.name.from_text("example.com.") ]
resolver.use_search_by_default = True
name = dns.name.from_text("www", origin=None)
answer = resolver.resolve(name, dns.rdatatype.A)
逆引き
Resolverには逆引き専用のメソッドresolve_addressが用意されている。resolve_addressは逆引きしたいIPアドレスを文字列で指定する。
import dns.resolver
resolver = dns.resolver.Resolver()
answer = resolver.resolve_address("1.1.1.1")
str(answer.rrset)
(out)'1.1.1.1.in-addr.arpa. 117 IN PTR one.one.one.one.'
通常のresolveメソッドで逆引きするには、逆引き用のin-addr.arpaアドレスで指定する必要がある。IPアドレスを逆引き用のアドレスに変換するdns.reversename.from_address関数が用意されている。
import dns.resolver
import dns.name
reversename = dns.reversename.from_address("1.1.1.1")
str(reversename)
(out)'1.1.1.1.in-addr.arpa.'
answer = dns.resolver.Resolver().resolve(reversename,dns.rdatatype.PTR)
str(answer.rrset)
(out)'1.1.1.1.in-addr.arpa. 1490 IN PTR one.one.one.one.'
例外処理
resolverメソッドはいくつかの例外が発生する。
| 例外クラス | 例外の状態 |
|---|---|
| dns.resolver.LifetimeTimeout | DNSサーバからの応答が時間内になかった。 |
| dns.resolver.NXDOMAIN | NXDOMAIN応答が返された。 (その名前のレコードがない) |
| dns.resolver.NoAnswer | NODATA応答が返された。ただし、resolveメソッドの引数でraise_on_no_answer=Trueのときのみ。デフォルトはTrue。 (その名前、クラス、型のレコードはないが他のクラス、型のレコードはある可能性がある) |
| dns.resolver.NoNameservers | 使用できるDNSサーバがない。 |
| dns.resolver.YXDOMAIN | 名前解決の途中でDNS名の長さ制限を超えた。 |
そのため本番コードでは、これらの例外を適切に扱うべきである。例えば以下のような実装が考えられる。
try:
resolver.resolve( "example.com", "A" )
except (dns.resolver.NoAnswer, dns.resolver.NXDOMAIN) as e:
# 問い合わせに対応するレコードがなかった場合の処理
except (dns.resolver.LifetimeTimeout, dns.resolver.NoNameservers, dns.resolver.YXDOMAIN) as e:
# 名前解決の実行が正しくできなかった場合の処理発生する例外によって処理が別れないならこれらの基底クラスdns.exception.DNSExceptionを使えば良い。
try:
resolver.resolve("example.com", "A")
except dns.exception.DNSException as e:
# ここで例外処理NoAnswer例外
NoAnswer例外はresolveメソッドの引数でraise_on_no_answer=Trueのとき(デフォルト)のみ発生する。raise_on_no_answer=Falseとすると、例外は発生せずAnswerのrrsetがNoneとなる。
import dns.resolver
resolver = dns.resolver.Resolver()
answer = resolver.resolve("www.example.com", "MX", raise_on_no_answer=False) # このレコードはAレコードはあるがMXレコードはない
print(answer.rrset)
(out)None
QueryMessage
Answerにも含まれるQueryMessageは実際にDNSサーバとやりとりするIDやフラグ、Opcodeなどを表すクラスである。これにより単純な名前解決の結果だけでなく、フラグなどの詳細な確認が行える。
import dns.resolver
resolver = dns.resolver.Resolver()
answer = resolver.resolve("example.com")
print(answer.response)
(out)id 46627
(out)opcode QUERY
(out)rcode NOERROR
(out)flags QR RD RA
(out);QUESTION
(out)example.com. IN A
(out);ANSWER
(out)example.com. 1536 IN A 93.184.215.14
(out);AUTHORITY
(out);ADDITIONAL
ゾーンファイルやリソースレコード
ここでは下図に示すクラスの概略とサンプルをいくつか示す。詳細はdnsppythonのドキュメントを参照すること。
RdataClass
RdataClassはリソースレコードのクラスを表すクラスであり、IntEnumを継承する列挙型である。dns.rdataclassモジュールに定数が用意されているのでそれを参照しても良い。
import dns.rdataclass
dns.rdataclass.RdataClass.IN
(out)<RdataClass.IN: 1>
dns.rdataclass.IN
(out)<RdataClass.IN: 1>
dns.rdataclass.RdataClass(1)
(out)<RdataClass.IN: 1>
RdataType
RdataTypeはリソースレコードのタイプを表すクラスであり、IntEnumを継承する列挙型である。dns.rdatatypeモジュールに定数が用意されているのでそれを参照しても良い。
import dns.rdatatype
dns.rdatatype.RdataType.MX
(out)<RdataType.MX: 15>
dns.rdatatype.A
(out)<RdataType.A: 1>
dns.rdatatype.RdataType(28)
(out)<RdataType.AAAA: 28>
Rdata
Rdataはリソースレコードのデータ部を表すクラスである。データ部はリソースレコードのクラス、タイプによってとる値が異なる。例えばAレコードであれば192.0.2.1のようなIPアドレスになるし、MXレコードであれば10 mx.example.comのような優先度とメールサーバの組み合わせになる。そのためRdataは基底クラスであり、クラスやタイプに応じたdns.rdtype.IN.A.Aやdns.rdtype.ANY.MX.MXなどを使っている。
Rdataを作るにはdns.rdata.from_text関数を使う。Rdataのクラス、タイプ、値はそれぞれrdclass属性、rdtype属性、to_textメソッドで取得できる。
import dns.rdata
rdatas = [
(con) dns.rdata.from_text(dns.rdataclass.IN, dns.rdatatype.A, '192.168.1.15'),
(con) dns.rdata.from_text(dns.rdataclass.IN, dns.rdatatype.MX, '10 mx.example.com'),
(con) ]
for rdata in rdatas:
(con) print(f"{type(rdata)}:{rdata}")
(con)
(out)<class 'dns.rdtypes.IN.A.A'>:192.168.1.15
(out)<class 'dns.rdtypes.ANY.MX.MX'>:10 mx.example.com
rdatas[0].rdclass
(out)<RdataClass.IN: 1>
rdatas[0].rdtype
(out)<RdataType.A: 1>
rdatas[0].to_text()
(out)'192.168.1.15'
Rdataset
datasetはクラス、タイプが同じRdataの集合である。Rdataに適用されるTTLの値も持つ。Rdatasetは作成済みのRdataから作る方法とテキストから作る方法がある。それぞれに可変長配列から作成するメソッドとリストから作成するメソッドが用意されている。
import dns.rdata
import dns.rdataset
rdatas = [
(con) dns.rdata.from_text("IN", "A", "192.0.2.100"),
(con) dns.rdata.from_text("IN", "A", "192.0.2.101"),
(con)]
# rdataから作成する方法
rdataset1 = dns.rdataset.from_rdata(3600, rdatas[0], rdatas[1])
rdataset2 = dns.rdataset.from_rdata_list(3600,rdatas)
# テキストから作成する方法
rdataset3 = dns.rdataset.from_text("IN","A", 3600, "192.0.2.100", "192.0.2.101")
rdataset4 = dns.rdataset.from_text_list("IN","A", 3600, ["192.0.2.100", "192.0.2.101"])
Rdatasetはイテラブルであり、シーケンスの記法で各Rdataの要素にアクセスできる。
import dns.rdataset
rdataset = dns.rdataset.from_text("IN","A", 3600, "192.0.2.100", "192.0.2.101")
str( rdataset[1] )
(out)'192.0.2.101'
Node
NodeはRdatasetのリストである。rdatasets属性がrdatasetのリストである。
Name
Nameはリソースレコードのドメイン名を表すクラスである。Nameはドメイン名をラベルのタプルとして管理する。
import dns.name
name = dns.name.from_text("www.example.com")
for label in name:
(con) print(label)
(con)
(out)b'www'
(out)b'example'
(out)b'com'
(out)b''
一般にピリオドで表されるルートドメインは、Nameでは空のラベルで表される。デフォルトでは自動でルードドメインが補完されるが、originで補完するドメインを指定できる。originをNoneとすると補完されなくなり、ルートドメインを含まない相対的なドメイン名として扱われる。
import dns.name
names = [
(con) dns.name.from_text("www.example.com."), # ルートドメインを明示したDNS名
(con) dns.name.from_text("www.example.com"), # ルートドメインを省略したDNS名
(con) dns.name.from_text("www", origin=None),
(con)]
for name in names:
(con) print(name)
(con) for label in name:
(con) print(label)
(con) print()
(con)
(out)www.example.com.
(out)b'www'
(out)b'example'
(out)b'com'
(out)b''
(out)
(out)www.example.com.
(out)b'www'
(out)b'example'
(out)b'com'
(out)b''
(out)
(out)www.example.com
(out)b'www'
(out)b'example'
(out)b'com'
(out)
(out)www
(out)b'www'
Nameのメソッド
Nameには階層構造に関連するメソッドが用意されている。なお、サンプルの前提としてnamesリストを以下のように定義済みである。
names = [
dns.name.from_text("example.com."),
dns.name.from_text("www.example.com."),
dns.name.from_text("example.com", origin=None),
dns.name.from_text("test", origin=None),
]| メソッド | 説明 | サンプル | サンプルの実行例 |
|---|---|---|---|
| parent() | ひとつ上の階層のNameを取得する。 | names[1].parent() | example.com. |
| canonicalize() | canonical formに直したNameを取得する。 | name = dns.name.from_text("EXAMPLE.com") | example.com. |
| relativize(origin:Name) | originからみた相対名を取得する。 | names[0].relativize(dns.name.root) | example.com www |
| derelativize(origin:Name) | 相対名であるNameをoriginをもとにした絶対名を取得する。 originは絶対名でなければならない。 | names[3].derelativize(names[0]) | test.example.com. |
| concatenate(other:Name) | Name同士を結合する。derelativizeと異なりotherは相対名でも良い。 メソッドの呼び出し側が絶対名の場合例外が発生する。 | names[3].concatenate(names[0]) | test.example.com. test.example.com |
| split(depth:int) | 指定の深さでNameを分割する。 | names[1].split(2) | (www.example, com.) |
| is_absolute() | ルートから始まる絶対名であればTrue。 | ||
| is_subdomain(other:Name) | otherのサブドメインであればTrue。同一のときもTrueとなる。 | ||
| is_superdomain(other:Name) | otherのスーパードメインであればTrue。同一のときもTrueとなる。 |
Name定数
dns.name.rootはルートをあらわすNameである。dns.name.Name("")と等しい。また空を表すNameとしてdns.name.emptyも用意されている。
RRset
RRsetはリソースレコードセットに対応するクラスである。名前解決の応答で用いられている。Rdatasetと同じくRdataから作成する方法とテキストから作成する方法の2つがあり、それぞれにリストの方法と可変長引数の方法がある。
RRsetはリソースレコードのowner、ttl、class、type、RDATAに対応する属性を持つ。RDATAはCollectionで管理されており、for ... inやrrset[x]のような形でRDATAにアクセスできる。
import dns.rdata
import dns.rrset
rdatas = [
(con) dns.rdata.from_text("IN", "A", "192.0.2.100"),
(con) dns.rdata.from_text("IN", "A", "192.0.2.101"),
(con)]
rrset = dns.rrset.from_rdata("www", 3600, *rdatas)
str( rrset.name ) # owner
(out)'www'
str( rrset.ttl ) # ttl
(out)'3600'
str( rrset.rdclass ) # class
(out)'1'
str( rrset.rdtype ) # type
(out)'1'
str( rrset.items ) # RDATAのCollection(実態はdict)
(out)'{: None, : None}'
for rdata in rrset:
(con) print( rdata )
(con)
(out)192.0.2.100
(out)192.0.2.101
Zone
ZoneはNameとNodeを対応させるクラスである。辞書と考えても良い。
import dns.zone
zone_text = """
(con)example.com. 3600 IN SOA ns1.example.com. (
(con) postmaster.example.com.
(con) 2023080001 ; Serial
(con) 3600 ; Refresh 1h
(con) 900 ; Retry 15m
(con) 604800 ; Expire 1w
(con) 3600 ) ; Negative cache TTL 15m
(con)example.com. 3600 IN NS ns-a.example.com.
(con) IN NS ns-b.example.com.
(con) 1800 IN MX 10 mx-a.example.com.
(con) IN MX 20 mx-b.example.com.
(con)ns-a 3600 IN A 192.0.2.100
(con)ns-b 3600 IN A 192.0.2.101
(con) IN A 192.0.2.102
(con) IN A 192.0.2.103
(con) IN A 192.0.2.104
(con)ns-b 600 IN TXT "example text"
(con)mx-a 3600 IN A 192.0.2.110
(con)mx-b 3600 IN A 192.0.2.111
(con)www.example.com. 3600 IN A 198.51.100.30
(con)"""
zone:dns.zone.Zone = dns.zone.from_text(zone_text, "example.com.")
for name in zone:
(con) print( f"\n######### {name} ##########" )
(con) node = zone[name]
(con) for rdatasetno,rdataset in enumerate(node,start=1):
(con) print(f"{rdatasetno}:{rdataset.rdtype!s}")
(con) print(rdataset)
(con)
(out)
(out)######### @ ##########
(out)1:6
(out)3600 IN SOA ns1 postmaster 2023080001 3600 900 604800 3600
(out)2:2
(out)3600 IN NS ns-a
(out)3600 IN NS ns-b
(out)3:15
(out)1800 IN MX 10 mx-a
(out)1800 IN MX 20 mx-b
(out)
(out)######### ns-a ##########
(out)1:1
(out)3600 IN A 192.0.2.100
(out)
(out)######### ns-b ##########
(out)1:1
(out)3600 IN A 192.0.2.101
(out)3600 IN A 192.0.2.102
(out)3600 IN A 192.0.2.103
(out)3600 IN A 192.0.2.104
(out)2:16
(out)600 IN TXT "example text"
(out)
(out)######### mx-a ##########
(out)1:1
(out)3600 IN A 192.0.2.110
(out)
(out)######### mx-b ##########
(out)1:1
(out)3600 IN A 192.0.2.111
(out)
(out)######### www ##########
(out)1:1
(out)3600 IN A 198.51.100.30
Zoneのキーはownerであり、zone[owner]のようにすることでNode単位でアクセスできる。それ以外にもrdata単位やrdataset単位でアクセスすることもできる。
for i in zone.iterate_rdatas():
(con) print(i)
(con)
(out)(, 3600, )
(out)(, 3600, )
(out)(, 3600, )
(out)(, 1800, )
(out)(, 1800, )
(out)(, 3600, )
(out)(, 3600, )
(out)(, 3600, )
(out)(, 3600, )
(out)(, 3600, )
(out)(, 600, )
(out)(, 3600, )
(out)(, 3600, )
(out)(, 3600, )
for i in zone.iterate_rdatasets():
(con) print(i)
(con)
(out)(, ]>)
(out)(, , ]>)
(out)(, , <20 mx-b>]>)
(out)(, ]>)
(out)(, , <192.0.2.102>, <192.0.2.103>, <192.0.2.104>]>)
(out)(, ]>)
(out)(, ]>)
(out)(, ]>)
(out)(, ]>)
条件を満たすものを取得するfind_node、find_rrset、find_rdatasetメソッドが用意されている。これらのメソッドは一致するものがなければ例外が発生する。例外を発生させるかわりにNoneを返すget_xxxxメソッドもある。
zone.find_node("www")
(out)
zone.find_rdataset("ns-b","A")
(out), <192.0.2.102>, <192.0.2.103>, <192.0.2.104>]>
zone.find_rrset(dns.name.empty,"NS")
(out), ]>
