awkコマンド
awkの特徴
awkは、CSVのように複数の項目に分割できるテキストレコードの加工や分析が得意なコマンドである。ファイアウォールのログを模したデータを使ってawkコマンドの特徴を見てみる。
2024/09/07 01:00:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,43256,443,allow,tcp-fin,1653,2456432
2024/09/07 01:01:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,31886,443,allow,tcp-rst-from-client,452,82673
2024/09/07 01:02:00,policy-2,INSIDE,192.168.1.11,DMZ,172.17.10.110,tcp,29243,443,allow,tcp-fin,328,2832
2024/09/07 01:03:00,policy-3,INSIDE,192.168.1.11,DMZ,172.17.10.120,tcp,41522,443,allow,ttcp-fin,9832,2398
2024/09/07 01:04:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,51102,443,allow,tcp-rst-from-client,23098797,913
2024/09/07 01:05:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.150,tcp,31810,80,allow,aged-out,10,0
2024/09/07 01:06:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.153,udp,48273,53,allow,aged-out,369,241
2024/09/07 01:07:00,policy-1,INSIDE,192.168.1.12,DMZ,172.17.10.100,tcp,41189,443,allow,ttcp-fin,947,8234
2024/09/07 01:08:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,25403,443,allow,ttcp-fin,654,2629
2024/09/07 01:09:00,policy-5,INSIDE,192.168.1.11,DMZ,172.17.10.150,tcp,61021,80,allow,aged-out,10,0
2024/09/07 01:10:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,13523,443,allow,tcp-rst-from-client,39,915
2024/09/07 01:11:00,policy-6,INSIDE,192.168.1.14,DMZ,172.17.10.153,udp,18292,53,allow,aged-out,823,432
2024/09/07 01:12:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,26714,443,allow,tcp-fin,1653,923479
2024/09/07 01:13:00,interzone-default,INSIDE,192.168.1.12,DMZ,172.17.10.150,tcp,41921,443,policy-deny,incomplete,42,0
2024/09/07 01:14:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,28907,443,allow,tcp-fin,568,5614
2024/09/07 01:15:00,policy-1,INSIDE,192.168.1.14,DMZ,172.17.10.100,tcp,39711,443,allow,tcp-fin,133,8031
これをsample.txtに保存した状態で、いくつかのawkコマンドを実行してみる。まずは「9番目の項目が53である行は、2番目の項目を出力せよ」という意味のawkコマンドである。
awk -F , '$9==53 {print $2}' sample.txt
(out)policy-1
(out)policy-6
続いて「4番目の項目が192.168.1.13である行について、12番目と13番目の項目の総合計を出力せよ」というコマンドを実行する。
awk -F , '$4=="192.168.1.13" { sum += $12+$13 }; END { print sum }' sample.txt
(out)23189627
以上のように、区切り文字で区切られたデータを処理することが得意なコマンドがawkである。
awkの基本
実行
awkコマンドの処理の流れは以下のようになる。
- データを行の区切りまで読み込む。行単位のデータをレコードと呼ぶ。
- レコードを区切り文字で分割する。分割したそれぞれの項目をフィールドと呼ぶ。
- ルールに従い処理する。ルールは処理対象のレコードを指定するパターンと、どのような処理をするか指定するアクションの組み合わせである。
- アクションの中でprintされたものが処理結果として出力される。
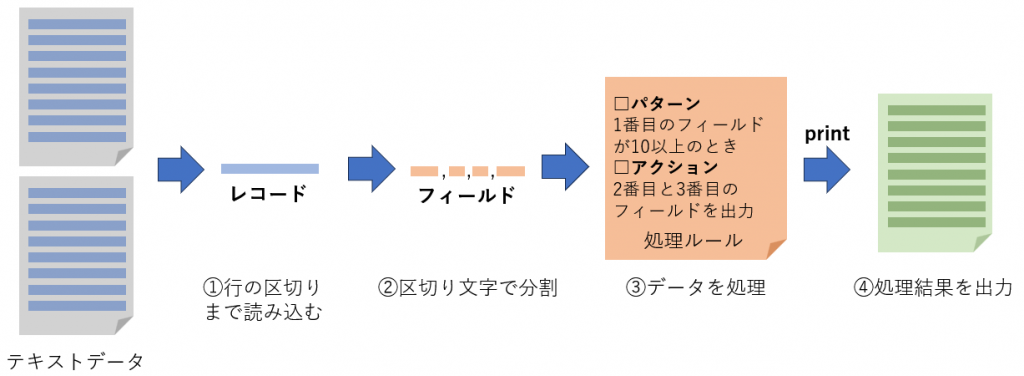
これを踏まえて、awkコマンドのよくある書き方を示す。
awk [オプション] -F 区切り文字 '処理ルール' テキストデータ1 [テキストデータ2 ... ]例1:awk -F , '$2 > 100 {print $1}' sample.txt sample2.txt
例2:awk '$2 > 100 {print $1}' sample.txt sample2.txt1つ目の例はsample.txtとsample2.txtの2つのファイルを入力として処理を行う。処理ルール$2 > 100 {print $1}は2番目のフィールドが100より大きいとき、1番目のフィールドを出力せよ、というものである。1つめの例ではFオプションによりフィールドの区切り文字として「,」を使用するよう指定している。なお、区切り文字のデフォルトは半角スペースであるため、区切り文字として半角スペースを使う場合は(2つ目の例のように)区切り文字の指定を省略できる。
処理ルールを別のファイルに書いておくこともできる。
awk [オプション] -f 処理ルールが書かれたファイル テキストデータ1 [テキストデータ2 ... ]例:awk -f command.awk sample.txt sample2.txtまた、処理する対象はファイルだけで無く、パイプで渡す、標準入力から渡すこともできる。
パイプで渡す :cat sample.txt | awk '{print $1}'
標準入力から渡す:awk '{print $1}' -レコードとフィールド
awkコマンドはデータを行単位で読み込む。行単位で読み込んだデータをレコードと呼ぶ。また、読み込んだレコードは区切り文字で分割する。分割したそれぞれのデータをフィールドとよぶ。レコードの内容は$0、フィールドの内容は$フィールド番号で参照できる。

末尾のフィールド
一番最後のフィールドや最後から2番目のフィールドのように後ろから数えた場所にあるフィールドを参照するにはNF(詳細は変数の節を参照)を使用する。一番最後のフィールドは$NFで、最後の1つ前のフィールドは$(NF-1)で参照できる。
レコードの区切り
設定により行単位(すなわち改行区切り)では無く、指定の区切り文字でレコードに分割できる。
処理ルール
awkではレコードに対してどのような処理を行うかを指定する。どのレコードに対して処理を行うかを指定するものをパターン、レコードに対してどのような処理を行うかを指定するものをアクションと呼び、pattern { action }のように書く。処理ルールはいくつも書くことができ、複数書いた場合は以下のようになる。
pattern1 { action1 }
pattern2 {
action2-1
action2-2
action2-3
action2-4
}
pattern3 { action3 }
...パターン
パターンはアクションを適用するレコードを指定するものである。パターンの書き方は2種類ある。
| 処理の対象 | パターンの書き方 |
|---|---|
| 条件に一致したレコード | condition { action } |
| 範囲内にあるレコード (開始条件に一致したレコードから終了条件に一致したレコードまでにあるレコード) | condition_start,condition_end { action } |
範囲の決定
範囲内にあるレコードで開始条件に一致すると、そのレコードに対してアクションが実行される。終了条件の検査は次のレコードから行われる。仮に開始条件と終了条件を同時に満たすレコードが出現した場合でも、範囲が開始すると同時に範囲が終了することはない。
範囲が開始し、終了した後も、引き続き開始条件に一致するレコードがないか検査される。つまりデータの中に複数の範囲が見つかることがある。
条件の主な書き方を示す。
| 条件の書き方 | 意味 |
|---|---|
| /regex/ | レコードが正規表現にマッチする |
| $n == "string" | n番目のフィールドが文字列と一致する |
| $n != "string" | n番目のフィールドが文字列と一致しない |
| $n ~ /regex/ | n番目のフィールドが正規表現とマッチする |
| $n !~ /regex/ | n番目のフィールドが正規表現とマッチしない |
| $n < value $n <= value $n >= value $n > value | (数値のフィールドに対して) n番目のフィールドの値が ・valueより小さい ・value以下である ・value以上である ・valueより大きい |
| FNR == n | (ファイルの先頭から数えて) n番目のレコードである |
| NR == n | (全ファイルを通して) n番目のレコードである |
| !condition | NOT条件(conditionが真でない) |
| condition1 && condition2 | AND条件(condition1もcondition2も真である) |
| condition1 || condition2 | OR条件(すくなくともcondition1かcondition2のどちらかは真である) |
パターンの省略
{ action }のようにパターンが省略された場合、全てのレコードに対して処理を行う。
特定のタイミング
特別なパターンとして、レコードを読み込み始める前および読み込み終わった後にアクションを行うためのパターンが用意されている。これは全レコードを集計するときなどに役立つ。
| 処理するタイミング | パターンの書き方 |
|---|---|
| 処理の最初 | BEGIN { action } |
| 処理の最後 | END { action } |
| ファイルの最初 | BEGINFILE { action } |
| ファイルの最後 | ENDFILE { action } |
アクション
アクションはレコードを加工したり、集計したりする処理を書くところである。また、printを使用してその結果を出力する。
処理した結果はprintを使うとレコードとして出力される。
print field1, field2, field3, ..., fieldNこれらのフィールドは組み込み変数OFSの値で区切られて出力され、末尾には組み込み変数ORSが出力される結果となる。
BEGIN {
OFS="<OFS>"
ORS="<<ORS>>"
}
END {
print "11", "12", "13"
print "21", "22", "23"
}
awk -f command.awk
(out)11<OFS>12<OFS>13<<ORS>>21<OFS>22<OFS>23<<ORS>>
なお、フィールドを1つも指定しなかった場合、$0が指定されているものと見なされる。
{
print # これは print $0 と同じ
}アクションの省略
アクションを省略した場合、{ print }が指定されたものと見なされる。
NR==3,NR==5 # これは NR==3,NR==5 { print } と同じパターンとアクションの例
ここではパターンとアクションを組み合わせた、実際に動作する処理内容の例を示す。
BEGIN {
print "action-BEGIN", FNR
}
/^2024\/09\/07 01:1/ {
print "action-1:", FNR
}
{
print "action-2:", FNR
}
END {
print "action-END:", FNR
}この例では4つの処理が書かれている。上から、処理が始まるとき、レコードが2024/09/07 01:1で始まるとき、すべてのレコード、処理が終わるときの処理である。各処理ではFNRを出力している。FNRとは現在処理中のファイルのレコード番号のことである。
これを上述のファイアウォールログsample.txtに対して実行してみる。すると、action-2がすべてのレコードに対して実行されていて、11行目からはaction-1も実行されていることが分かる。これは11行目からaction1の実行条件/^2024\/09\/07 01:1/を満たすようになったためである。
awk -F , -f command.awk sample.txt
(out)action-BEGIN 0
(out)action-2: 1
(out)action-2: 2
(out)action-2: 3
(out)action-2: 4
(out)action-2: 5
(out)action-2: 6
(out)action-2: 7
(out)action-2: 8
(out)action-2: 9
(out)action-2: 10
(out)action-1: 11
(out)action-2: 11
(out)action-1: 12
(out)action-2: 12
(out)action-1: 13
(out)action-2: 13
(out)action-1: 14
(out)action-2: 14
(out)action-1: 15
(out)action-2: 15
(out)action-1: 16
(out)action-2: 16
(out)action-END: 16
変数
awkでは変数に値を記憶することができる。これを利用して値を集計したり、あるワードの出現回数を数えたりできる。
awkが定義する変数(組み込み変数)
awkにはあらかじめ定義された、すなわちawkが処理で使用する変数がある。これを組み込み変数とよぶ。組み込み変数は、awkの動作に影響するものとawkの状態を表すものの2つがある。
awkの動作を決める組み込み変数
アクションの例では以下のコマンドを実行した。
awk -F , -f command.awk sample.txt
これは別の書き方で以下のように書ける。
awk -v FS="," -f command.awk sample.txt
-vオプションは変数の値を指定するもので、この例ではFSという変数の値を“,”に指定している。このFSは動作を決める組み込み変数の一つであり、フィールドの区切り文字(フィールドセパレータ)を意味している。-Fオプションは区切り文字を指定するコマンドオプションであり、これらは書き方は違うが同じことを意味している。
このようなawkの動作を決める組み込み変数の主なものを示す。
| 組み込み変数 | 意味 |
|---|---|
| FS | 入力データのフィールド区切り文字、または区切りとして使う正規表現。 ""(空文字)の場合は1文字ごとにフィールドを分割する。 デフォルト値は” ”(半角空白)。 |
| RS | 入力データのレコード区切り文字。 |
| OFS | 出力データのフィールド区切り文字。 |
| ORS | 出力データのレコード区切り文字。 |
| IGNORECASE | この値が非0のとき、文字列を比較するときに大文字小文字を区別しない。 |
awkの状態を表す組み込み変数
すでに登場したFNRやNRのように、awkの状態を表す変数として以下のようなものがある。
| 組み込み変数 | 意味 |
|---|---|
| NR | awkを開始してから処理したレコードの総数。 |
| FNR | 現在のファイルの処理を開始してから処理したレコードの総数。 |
| NF | 現在処理中のレコードのフィールド数。 |
| FILENAME | 処理中のファイル名。 入力がパイプで与えられた場合、ファイル名がないため"-"となる。 |
独自変数
組み込み変数でなく、ifなどのキーワードでもなければ、自由にユーザ定義変数として利用できる。以下はABCという名前の変数の内容を出力する。
{
print ABC
}awkでは変数を宣言すること無く利用でき、全ての独自変数は初期値が数値であれば0、文字列であれば""(空文字列)として扱われる。この例では変数ABCを初期化しないで出力しているが、awkではエラーにならない。
変数の型
awkでは変数は配列か非配列(スカラー)かのどちらかである。変数がどちらかは最初にその変数をどちらとして使用するかで決まる。一度スカラーとして初期化した変数を、配列として使うことはできない。例示はしないが逆も同様である。
BEGIN {
abc = "text" # これで変数abcはスカラーになる。
abc["key"] = "text" # これはスカラー変数abcを配列のように使用しているためエラーになる
}
awk -f command.awk sample.txt
(out)awk: command.awk:3: fatal: attempt to use scalar `abc' as an array
スカラー
配列でない単一の値を持つ変数をスカラーという。awkでは変数の値は文字列である。しかし必要に応じて数値としても振る舞う。数値でない文字列や空文字列が数値として振る舞うとき、値は0になる。
BEGIN {
NAME = "12"
print NAME + 1
NAME = "a12"
print NAME + 1
}
awk -F , -f command.awk sample.txt
(out)13
(out)1
この例では、はじめにNAME変数を「12」という文字列で初期化して、それに1を足している。そのとき、awkはNAMEを自動で数値に変換するため、計算結果は13になる。つぎにNAMEを「a12」という文字列で同じことを行う。同様にawkはNAMEを数値に変換しようとするが、「a12」は数値ではないため、0として取り扱われる。そのため計算結果は1となる。
別の例として、初期化していない変数に演算を行う例を示す。これは数値として扱われているため初期値は0となる。
BEGIN {
print NAME + 1
}
awk -F , -f command.awk sample.txt
(out)1
regexp型
正規表現を変数に代入するときは/regexp/ではなく@/regexp/を使う。これはgawkの独自拡張である。
BEGIN {
reg1 = /abc/
reg2 = @/abc/
print "reg1:", reg1
print "reg2:", reg2
}
awk -f command.awk
(out)reg1: 0
(out)reg2: abc
文脈によるが reg1 = /abc/のような正規表現の変数への代入は、reg1 = $0 ~ /abc/のように解釈されることが多い。つまり正規表現そのものではなく、比較対象が省略された正規表現演算と見なされてしまう。@を頭に付けることで、正規表現そのものを変数に格納できる。この@が付いた正規表現をStrongly typed regexp constants(直訳:厳密に型指定された正規表現定数)とよぶ。これが代入された変数はregexp型になる。
正規表現定数の制限
正規表現定数およびregexp型の変数は使用できる場所に制限がある。
- 正規表現演算子(~と!~)の右辺の値
- switch文の条件値
- 正規表現を受け取る関数の引数の値
- 独自関数の引数および戻り値
- 変数へ代入する値(代入式の右辺の値)
regexp型の変換
regexp型は数値では0、文字列では正規表現を表す文字に変換される。
配列
awkの配列は連想配列である。他言語でも良くある[]で要素を取得でき、キーとして文字列が使われる。配列変数の初期値は空の配列である。存在しない要素にアクセスするとスカラーと同様に空文字列で初期化される。
BEGIN {
capital["日本"] = "東京"
capital["アメリカ"] = "ワシントンD.C."
}
END {
print capital["アメリカ"], capital["イギリス"], capital["日本"]
}
awk -f command.awk sample.txt
(out)ワシントンD.C.,,東京
この例ではcapital["日本"] = "東京"の時点で、capitalが配列変数として初期化される。後に初期化していないcapital["イギリス"]へアクセスしているが、エラーとはならずcapital["イギリス"]は空文字列で初期化される。実際にcapital["イギリス"]を参照した後で、すべてのcapitalを表示させてみる。
BEGIN {
capital["日本"] = "東京"
capital["アメリカ"] = "ワシントンD.C."
}
END {
print capital["アメリカ"], capital["イギリス"], capital["日本"]
for( nation in capital ) {
print nation, capital[nation]
}
}
awk -f command.awk sample.txt
(out)ワシントンD.C.,,東京
(out)アメリカ ワシントンD.C.
(out)イギリス
(out)日本 東京
イギリスが配列capitalに追加されていることが分かる。
delete
deleteを使うと配列の要素を削除できる。
BEGIN {
capital["日本"] = "東京"
capital["アメリカ"] = "ワシントンD.C."
delete capital["日本"]
for( nation in capital ) {
print nation, capital[nation]
}
}
awk -f command.awk sample.txt
(out)アメリカ ワシントンD.C.
配列のインデックスを指定しないと配列を空にできる。
BEGIN {
capital["日本"] = "東京"
capital["アメリカ"] = "ワシントンD.C."
delete capital
for( nation in capital ) {
print nation, capital[nation]
}
}
awk -f command.awk sample.txt
(out)(何も表示されない)
変数の初期化
変数の初期値が""または0で問題無いなら、変数を初期化しなくても動作する。初期化するときはBEGINまたはBEGINFILEのアクションで行うことがある。
BEGIN {
NAME = "text"
}
{
print NAME
}
awk -F , -f command.awk sample.txt
(out)text
(out)text
(out)(省略)
変数のスコープ
変数の初期化の例を見ると分かるように、変数はawk内のどこでも使用できる。基本的にawkの変数は大域変数である。ただし後述する関数の引数はローカル変数となる。
アクションの記法
文字列の結合
文字列を結合するときは" "(半角空白)で区切って書く。+では数値として演算が行われてしまう。
BEGIN {
ABC = "text"
print ABC ABC
}
awk -F , -f command.awk sample.txt
(out)texttext
awk特有の制御構文
処理は条件がBEGINやENDなどのときを除いて上から順に行われる。もしBEGINやENDが複数回指定されている場合は、その中で上から実行される。
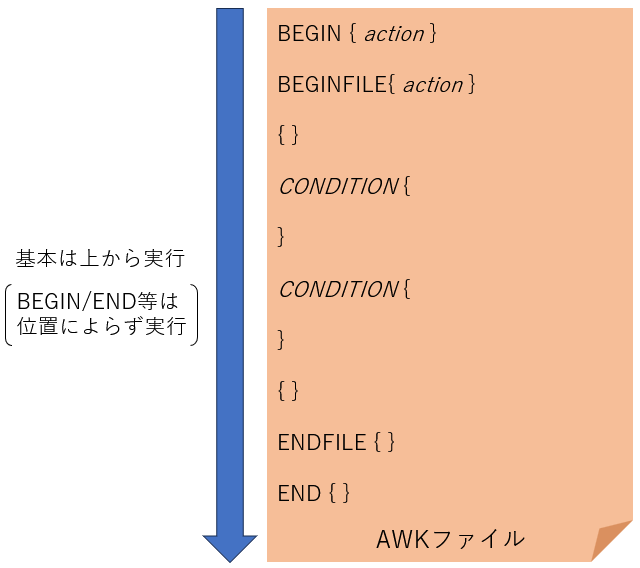
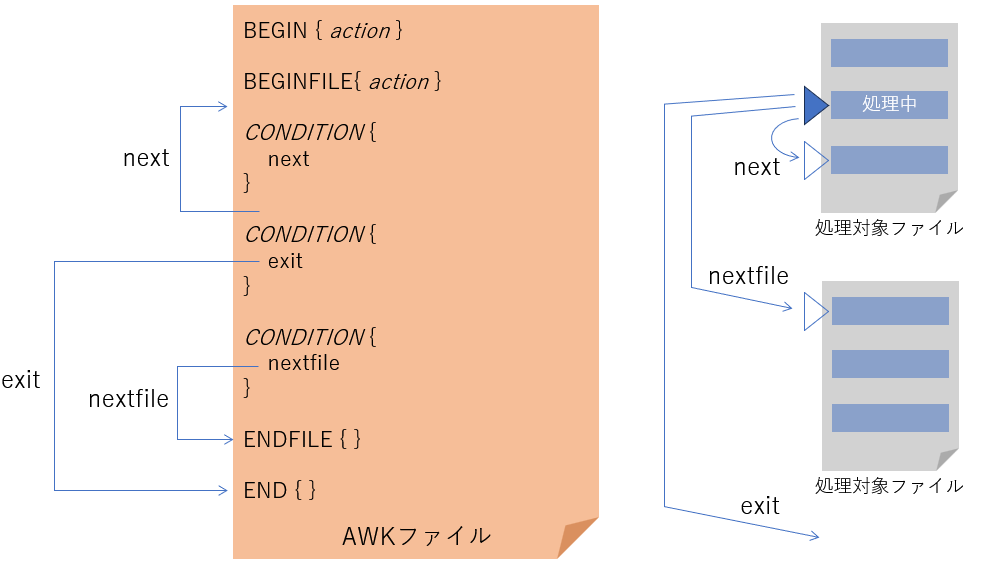
この処理の流れを途中で中断するawk特有の制御構文を示す。
| 構文 | 意味 |
|---|---|
| next | 現在のレコード処理を終了し、次のレコードに移る。 |
| nextfile | 現在のファイル処理を終了し、次のファイルに移る。 |
| exit | awkを終了する。 現在のファイルは強制終了の扱いとなりENDFILEが実行されない。 ただし、ENDは実行される。 |
一般的な制御構文
awkはよくあるプログラミング言語の構文におおむね対応しており、柔軟に処理が指定できる。ここではアクションで利用できる主な構文を示す。
| 条件分岐(if) | if ( condition1 ) { |
| 条件分岐(switch...case) | switch( 変数名 ) { |
| 繰り返し(for) | for( 初期化; 反復条件; 再設定){ |
| 繰り返し(while) | while( 反復条件 ){ |
| 繰り返し(do...while) | do { |
| 配列に対しての繰り返し(for in) | for( 変数名 in 配列 ){ |
関数
独自関数
functionで関数を作成できる。
function add1(x) {
return x+1
}
{
print add1(FNR)
}関数の引数は大域変数では無くローカル変数となる。
文字列を操作する関数
文字列を操作する関数を紹介する。主な文字列操作関数の説明を以下に示す。関数によって値が書き換えられる引数に<out>と記載している。
| 関数 | 意味 | 備考 |
|---|---|---|
index( text, searchtext ) | textの中でsearchtextを検索し、インデックスを返す。 | |
length( text ) | textの文字数を返す。 | |
split( text, <out> result, separator ) | textをseparatorで分割したものをresultに格納する。 分割した個数を返す。 | resultは結果が格納できる変数で無ければならない。 |
sub( regex, replace, <out> text )gsub( regex, replace, <out> text ) | textでregexにマッチしたものをreplaceに置換し、textに格納する。 置換した個数を返す。 | subは一番左でマッチしたものを置換し、gsubはマッチしたものを全て置換する。 textは入力であり、出力でもある。 |
gensub( regex, replace, index, text) | textでregexにindex番目にマッチしたものをreplaceに置換して返す。 indexに"g"を指定した場合、全て置換する。 | これはsub、gsubとは異なり、textを書き換えない。 |
substr( text, start, length) | textの部分文字列を取り出す。 | |
toupper( text )tolower( text ) | textを大文字/小文字にしたものを返す。 |
実際に文字列操作を行う例を示す。
# textfunction.awk
BEGIN {
text="a,ab,abc,abcd,abcde,abcdef,abcdefg"
OFS=" :"
print "text", text
print "index", index(text, "cde")
print "length", length(text)
print "split", split(text, result, ",")
for(r in result){
print " result[" r "]", result[r]
}
target = text
print "sub", sub( /.cd?e?,/, "!", target)
print " result", target
target = text
print "gsub", gsub( /.cd?e?,/, "!", target)
print " result", target
target = text
print "gensub", gensub( /.cd?e?,/, "!", 1, target)
print "gensub", gensub( /.cd?e?,/, "!", 2, target)
print "gensub", gensub( /.cd?e?,/, "!", "g", target)
print " after", target
print "substr", substr(text, 5, 3)
print "upper", toupper(text)
print "lower", tolower("UpperText")
}
awk -f textfunction.awk
(out)text :a,ab,abc,abcd,abcde,abcdef,abcdefg
(out)index :17
(out)length :34
(out)split :7
(out) result[1] :a
(out) result[2] :ab
(out) result[3] :abc
(out) result[4] :abcd
(out) result[5] :abcde
(out) result[6] :abcdef
(out) result[7] :abcdefg
(out)sub :1
(out) result :a,ab,a!abcd,abcde,abcdef,abcdefg
(out)gsub :3
(out) result :a,ab,a!a!a!abcdef,abcdefg
(out)gensub :a,ab,a!abcd,abcde,abcdef,abcdefg
(out)gensub :a,ab,abc,a!abcde,abcdef,abcdefg
(out)gensub :a,ab,a!a!a!abcdef,abcdefg
(out) after :a,ab,abc,abcd,abcde,abcdef,abcdefg
(out)substr :,ab
(out)upper :A,AB,ABC,ABCD,ABCDE,ABCDEF,ABCDEFG
(out)lower :uppertext
続いて正規表現でパターンマッチする関数matchを紹介する。
| 関数 | 意味 | 備考 |
|---|---|---|
match( text, regex ) | textをregexでマッチする。最初にマッチしたインデックスを返す。 また、RSTARTとRLENGTHにマッチしたインデックスとマッチした長さが格納される。これを利用してsubstrで一致した文字列を取り出すことができる。 | |
match( text, regex, <out> group ) | 上のmatchの動作に加え、groupにキャプチャグループでキャプチャされた内容、インデックス情報が格納される。 | groupは配列でなければならない。 groupにキャプチャされる情報は以下である。 ・group[キャプチャグループ番号]:キャプチャした文字列 ・group[キャプチャグループ番号, "start"]:キャプチャした文字列のインデックス ・group[キャプチャグループ番号, "length"]:キャプチャした文字列の長さ |
# regexfunction.awk
BEGIN {
text="a,ab,abc,abcd,abcde,abcdef,abcdefg"
OFS=" :"
print "text", text
print "match", match(text, /,a.*[ef],/)
print " RSTART", RSTART
print " RLENGTH", RLENGTH
print " substr", substr(text, RSTART, RLENGTH)
print "match", match(text, /,ab?([^,]{3}),/, group)
print " group[1]", group[1]
print " group[1, \"start\"]", group[1, "start"]
print " group[1, \"length\"]", group[1, "length"]
}
awk -f regexfunction.awk
(out)text :a,ab,abc,abcd,abcde,abcdef,abcdefg
(out)match :2
(out) RSTART :2
(out) RLENGTH :26
(out) substr :,ab,abc,abcd,abcde,abcdef,
(out)match :9
(out) group[1] :bcd
(out) group[1, "start"] :11
(out) group[1, "length"] :3
その他の関数
awkには他にも数値に関する関数、入出力に関する関数、時刻に関する関数などがある。これらについてはドキュメントを参照すること。
シェル
処理ルールをワンライナーで書く
簡単な処理であればシェルコマンドの引数で処理ルールを指定できる。ワンライナーで処理ルールを書くときは;で区切りを示す。;は処理ルールの区切りと、連続する処理の区切りの位置に必要となる。
以下の処理をワンライナーで渡したいとする。
$3~keyword{
print
}
NR % 2 == 0 {
print $1
print $2
if($3!=""){
print $3
print $4,$5,$6
print $7
}
}
BEGIN {
FS=","
OFS=","
keyword=@/10[0-9]{3}/
}この処理をワンライナーにするときに区切り文字;が必要な場所は以下のところである。
$3~keyword{
print
}; # 処理ルールの区切り
NR % 2 == 0 {
print $1; # 連続する処理の区切り
print $2; # 連続する処理の区切り
if($3!=""){
print $3; # 連続する処理の区切り
print $4,$5,$6; # 連続する処理の区切り
print $7
}
}; # 処理ルールの区切り
BEGIN {
FS=","; # 連続する処理の区切り
OFS=","; # 連続する処理の区切り
keyword=@/10[0-9]{3}/
}これから改行を取り除くとワンライナーのコマンドが完成する。
$3~keyword{print}; NR % 2 == 0 {print $1;print $2;if($3!=""){print $3;print $4,$5,$6;print $7}};
BEGIN{FS=",";OFS=",";keyword=@/10[0-9]{3}/}セミコロンの位置
すべての行、アクションの終わりに;を付けても動作する。
$3~keyword{print;}; NR % 2 == 0 {print $1;print $2;if($3!=""){print $3;print $4,$5,$6;print $7;}};BEGIN{FS=",";OFS=",";keyword=@/10[0-9]{3}/};
ただし、パターンの後ろにセミコロンを付けると意味が変わるため注意すること。たとえば
NR % 2 == 0; { print $1; };
は以下のようなアクションを省略した処理ルールとパターンを省略した処理ルールの2つとして解釈される。
NR % 2 == 0 { print }; 1 { print $1 }'
パイプでawkを使用するときの注意点
ファイル名
当然ながらパイプで渡された内容はファイル名を取得できない。
cat sample.txt sample2.txt | awk -F , 'BEGINFILE { print FILENAME }'
(out)-
(out)
awk -F , 'BEGINFILE { print FILENAME }' sample.txt sample2.txt
(out)sample.txt
(out)sample2.txt
nextfile
ファイル名の取得の例を見て分かるように、パイプで渡される内容はawk側では1つのファイルのように扱われる。そのため、nextfileで次のファイルへ移ることはできない。単にパイプで渡されるデータをこれ以上処理しないことになる。
シェルコマンドを実行する
system
systemを使うとシェルコマンドを実行できる。systemはコマンドの実行ステータスを返す。
awk 'BEGIN{ RESULT=system("ls"); printf "result:%s,%d\n", typeof(RESULT), RESULT}'
(out)sample.txt sample2.txt sample3.txt
(out)result:number,0
geline
getlineを使うとシェルコマンドを実行し、その出力をawkで処理できる。lsコマンドを実行する例を示す。
BEGIN {
"ls" | getline var
print var
}
awk -F , -f command.awk sample.txt
(out)command.awk
この書き方ではgetlineで1行目の出力結果しか得ることができない。whileと組み合わせると全ての結果が得られる。
BEGIN {
while (("ls" | getline var) > 0) {
print var
}
}
awk -F , -f command.awk sample.txt
(out)command.awk
(out)sample.txt
(out)sample2.txt
getlineでは書き方によって使い方がいくつかある。例えばファイルから読み込むこともgetlineで行える。詳細はマニュアルを参照すること。
getlineによる変数書き換え
getlineは使い方によって処理中のレコードの値やNF等の値を書き換えることがある。
シェルからパラメータを受け取る
vオプションで変数に値を設定する。たとえば条件に一致した行だけ出力するが、その条件自体はコマンドラインで指定するような場合に利用できる。
$0 == keyword {
print
}
awk -v keyword="192.168.1.10" -F , -f command.awk sample.txt
(out)2024/09/07 01:00:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,43256,443,allow,tcp-fin,1653,2456432
(out)2024/09/07 01:05:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.150,tcp,31810,80,allow,aged-out,10,0
(out)2024/09/07 01:10:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,13523,443,allow,tcp-rst-from-client,39,915
エスケープ処理
vオプションの値はawkによってエスケープ処理が行われる。KEYWORD変数を表示するコマンドをKEYWORDを変えながら実行してみると、awkが対応していないエスケープシーケンスを含むKEYWORDのきには警告メッセージが表示されてエスケープ文字\が無視される。
awk -v KEYWORD="TEST" 'BEGIN{printf "\"%s\"\n", KEYWORD}'
(out)"TEST"
awk -v KEYWORD="\t" 'BEGIN{printf "\"%s\"\n", KEYWORD}'
(out)" "
awk -v KEYWORD="\ " 'BEGIN{printf "\"%s\"\n", KEYWORD}'
(out)awk: warning: escape sequence `\ ' treated as plain ` '
(out)" "
なお、vオプションの値を引用符でくくらない場合はシェルによるエスケープ処理も行われる。
awk -v KEYWORD=t 'BEGIN{printf "\"%s\"\n", KEYWORD}'
(out)'t'
awk -v KEYWORD=\t 'BEGIN{printf "\"%s\"\n", KEYWORD}'
(out)'t'
awk -v KEYWORD=\\t 'BEGIN{printf "\"%s\"\n", KEYWORD}'
(out)' '
正規表現を受け取る
正規表現を受け取るときは正規表現定数を使う。
$0 ~ keyword {
print
}
awk -v KEYWORD="@/192\.168\.1\.1[23]/" '$0~KEYWORD' sample.txt
(out)2024/09/07 01:01:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,31886,443,allow,tcp-rst-from-client,452,192116871410
(out)2024/09/07 01:02:00,policy-2,INSIDE,192.168.1.11,DMZ,172.17.10.110,tcp,29243,443,allow,tcp-fin,328,2832
(out)省略
もし正規表現定数を使わずに渡そうとするとエスケープ処理が行われる点に注意が必要である。
awkの使用例
以下のテキストデータsample.txtを処理するawkコマンドの例をいくつか示す。
2024/09/07 01:00:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,43256,443,allow,tcp-fin,1653,2456432
2024/09/07 01:01:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,31886,443,allow,tcp-rst-from-client,452,82673
2024/09/07 01:02:00,policy-2,INSIDE,192.168.1.11,DMZ,172.17.10.110,tcp,29243,443,allow,tcp-fin,328,2832
2024/09/07 01:03:00,policy-3,INSIDE,192.168.1.11,DMZ,172.17.10.120,tcp,41522,443,allow,ttcp-fin,9832,2398
2024/09/07 01:04:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,51102,443,allow,tcp-rst-from-client,23098797,913
2024/09/07 01:05:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.150,tcp,31810,80,allow,aged-out,10,0
2024/09/07 01:06:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.153,udp,48273,53,allow,aged-out,369,241
2024/09/07 01:07:00,policy-1,INSIDE,192.168.1.12,DMZ,172.17.10.100,tcp,41189,443,allow,ttcp-fin,947,8234
2024/09/07 01:08:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,25403,443,allow,ttcp-fin,654,2629
2024/09/07 01:09:00,policy-5,INSIDE,192.168.1.11,DMZ,172.17.10.150,tcp,61021,80,allow,aged-out,10,0
2024/09/07 01:10:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,13523,443,allow,tcp-rst-from-client,39,915
2024/09/07 01:11:00,policy-6,INSIDE,192.168.1.14,DMZ,172.17.10.153,udp,18292,53,allow,aged-out,823,432
2024/09/07 01:12:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,26714,443,allow,tcp-fin,1653,923479
2024/09/07 01:13:00,interzone-default,INSIDE,192.168.1.12,DMZ,172.17.10.150,tcp,41921,443,policy-deny,incomplete,42,0
2024/09/07 01:14:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,28907,443,allow,tcp-fin,568,5614
2024/09/07 01:15:00,policy-1,INSIDE,192.168.1.14,DMZ,172.17.10.100,tcp,39711,443,allow,tcp-fin,133,8031指定された行範囲のレコードを出力する
あらかじめ処理したい行番号の範囲が分かっている場合は行範囲を指定して処理できる。
awk -F , 'FNR==6,FNR==10{print}' sample.txt
(out)2024/09/07 01:05:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.150,tcp,31810,80,allow,aged-out,10,0
(out)2024/09/07 01:06:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.153,udp,48273,53,allow,aged-out,369,241
(out)2024/09/07 01:07:00,policy-1,INSIDE,192.168.1.12,DMZ,172.17.10.100,tcp,41189,443,allow,ttcp-fin,947,8234
(out)2024/09/07 01:08:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,25403,443,allow,ttcp-fin,654,2629
(out)2024/09/07 01:09:00,policy-5,INSIDE,192.168.1.11,DMZ,172.17.10.150,tcp,61021,80,allow,aged-out,10,0
指定された時間の範囲のレコードを出力する
今回のデータでは1番目のフィールドが時間を表している。1番目のフィールドが調査したい時間のものだけを出力する例を示す。
awk -F ',' '$1~/2024\/09\/07 01:03/,$1~/2024\/09\/07 01:09/ {print}' sample.txt
(out)2024/09/07 01:03:00,policy-3,INSIDE,192.168.1.11,DMZ,172.17.10.120,tcp,41522,443,allow,ttcp-fin,9832,2398
(out)2024/09/07 01:04:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,51102,443,allow,tcp-rst-from-client,23098797,913
(out)2024/09/07 01:05:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.150,tcp,31810,80,allow,aged-out,10,0
(out)2024/09/07 01:06:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.153,udp,48273,53,allow,aged-out,369,241
(out)2024/09/07 01:07:00,policy-1,INSIDE,192.168.1.12,DMZ,172.17.10.100,tcp,41189,443,allow,ttcp-fin,947,8234
(out)2024/09/07 01:08:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,25403,443,allow,ttcp-fin,654,2629
(out)2024/09/07 01:09:00,policy-5,INSIDE,192.168.1.11,DMZ,172.17.10.150,tcp,61021,80,allow,aged-out,10,0
条件を満たすレコードを出力する
12番目のフィールドが1000以上の場合に処理する例を示す。アクションを省略した記法であり、$12>=1000 {print $0}としても同じ結果になる。
awk -F ',' '$12>=1000' sample.txt
(out)2024/09/07 01:00:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,43256,443,allow,tcp-fin,1653,2456432
(out)2024/09/07 01:03:00,policy-3,INSIDE,192.168.1.11,DMZ,172.17.10.120,tcp,41522,443,allow,ttcp-fin,9832,2398
(out)2024/09/07 01:04:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,51102,443,allow,tcp-rst-from-client,23098797,913
(out)2024/09/07 01:12:00,policy-1,INSIDE,192.168.1.11,DMZ,172.17.10.100,tcp,26714,443,allow,tcp-fin,1653,923479
また、パターンではなくif文でも実現できる。状況に応じて使いやすい方を使えば良い。
{
if( $12 > 1000 ){
print $0
}
}値の出現回数を数える
4番目のフィールドにある値が何回出現したか集計する例を示す。
{
key = $4
count[key] += 1
}
END {
for(c in count) {
print c, count[c]
}
}
awk -F , -f command.awk sample.txt
(out)192.168.1.10 3
(out)192.168.1.11 5
(out)192.168.1.12 2
(out)192.168.1.13 4
(out)192.168.1.14 2
countという連想配列で出現回数を数える。数えたい値を連想配列のキーとして使うことで、目的を実現している。そしてENDのアクション内でfor ... inを使用して結果を表示している。もし複数のフィールドをキーとして件数を数えたい場合、以下のようにフィールドを結合したものをキーとすれば良い。
{
key = $6 ":" $9
count[key] += 1
}
END {
for(c in count) {
print c, count[c]
}
}
awk -F , -f command.awk sample.txt
(out)172.17.10.100:443 9
(out)172.17.10.153:53 2
(out)172.17.10.150:443 1
(out)172.17.10.150:80 2
(out)172.17.10.120:443 1
(out)172.17.10.110:443 1
重複を排除する
値の出現回数を求めるのと同じ考え方をパターンで使用すれば、重複を排除することもできる。以下は4番目の値が初めて出現した値であれば出力するものである。
awk -F , '!count[$4]++{print}' sample.txt
(out)2024/09/07 01:00:00,policy-1,INSIDE,192.168.1.10,DMZ,172.17.10.100,tcp,43256,443,allow,tcp-fin,1653,2456432
(out)2024/09/07 01:01:00,policy-1,INSIDE,192.168.1.13,DMZ,172.17.10.100,tcp,31886,443,allow,tcp-rst-from-client,452,82673
(out)2024/09/07 01:02:00,policy-2,INSIDE,192.168.1.11,DMZ,172.17.10.110,tcp,29243,443,allow,tcp-fin,328,2832
(out)2024/09/07 01:07:00,policy-1,INSIDE,192.168.1.12,DMZ,172.17.10.100,tcp,41189,443,allow,ttcp-fin,947,8234
(out)2024/09/07 01:11:00,policy-6,INSIDE,192.168.1.14,DMZ,172.17.10.153,udp,18292,53,allow,aged-out,823,432
合計値を求める
12番目のフィールドの合計値をそれぞれ求める例を示す。
awk -F ',' '{sent+=$12}; END{print sent}' sample.txt
(out)23116310 3494823
平均値を求める
12番目のフィールドの平均値を求める例を示す。
awk -F ',' '{count+=1;sent+=$12};END{print sent,count,sent/count}' sample.txt
(out)23116310 16 1.44477e+06
この処理ルールを改行を入れて書くと以下のようになる。
{
count += 1
sent += $12
}
END {
print sent, count, sent/count
}合計値や平均値を条件別に求める
今回のデータは4番目に通信の送信元IPアドレスが、12番目に送信したバイト数が入っている。送信元IPアドレスごとに何バイト送信したか集計する例を示す。
awk -F ',' '{key=$4;count[key]+=1;sent[key]+=$12};END{for(key in sent){print key,count[key],sent[key]/count[key]}}' sample.txt
(out)192.168.1.10 1702 3 567.333
(out)192.168.1.11 12477 5 2495.4
(out)192.168.1.12 989 2 494.5
(out)192.168.1.13 23100186 4 5.77505e+06
(out)192.168.1.14 956 2 478
ワンライナーでは分かりにくいため、改行を入れた処理ルールを以下に示す。
{
key = $4
count[key] += 1
sent[key] += $12
}
END {
for(key in count){
print key, count[key], sent[key]/count[key]
}
}CSVを読み込む(簡易)
フィールドの区切り文字を","にするには-Fオプションを使用する。このサンプルは読み込むCSVデータによって正しく処理できないことがある。次の例で補足する。
awk -F ',' '{print $4,$6}' sample.txt
(out)192.168.1.10 172.17.10.100
(out)192.168.1.13 172.17.10.100
(out)192.168.1.11 172.17.10.110
(out)(省略)
CSVを読み込む(発展)
簡易版ではフィールドの値に「,」が含まれるCSVで区切りがおかしくなる。以下の表データをCSV化したものをcsverror.txtとして保存した。
| csv,test | csv | test |
| "csv","test" | csv | test |
| csvtest | csvtest |
"csv,test",csv,test
"""csv"",""test""",csv,test
csvtest,,csvtestこれをawkでカンマ区切りとして処理すると、csv,testや"csv","test"が2つのフィールドに分かれてしまう。
awk -F , '{for(i=1;i<=NF;++i){printf "%d:%10-s", i, $i} printf "%s", ORS}' csverror.txt
(out)1:"csv 2:test" 3:csv 4:test
(out)1:"""csv"" 2:""test""" 3:csv 4:"test"
(out)1:csvtest 2: 3:csvtest
FPAT
FPATという組み込み変数を使うとより正確にCSVを読み込むことができる。ただ、完全ではない。
これまではフィールドを区切る文字を指定することでレコードを分割していた。組み込み変数FPATは逆の考え方で、フィールドが「どのようなフォーマットかを正規表現で指定」し、それに従ってレコードを分割する。FPATを使用してCSVを読み込む例を示す。
awk -v FPAT='[^,]*|\"[^\"]*\"' '{for(i=1;i<=NF;++i){printf "%d:%15-s", i, $i} printf "\n"}' csve
rror.txt
(out)1:"csv,test" 2:csv 3:test
(out)1:"""csv"" 2:""test""" 3:csv 4:"test"
(out)1:csvtest 2: 3:csvtest
この例で使用した正規表現FPAT、[^,]*|\"[^\"]*\"はREGEXPERでは以下のように図示される。この正規表現は「,を含まない文字列」「空文字列」「二重引用符で囲まれている文字列」を意味しており、awkはこれに一致したものを1つのフィールドとして扱う。この正規表現は"csv,test"という値を正しく1つのフィールドとして扱うことができるが、"""csv"",""test"""は正しく分割できない。
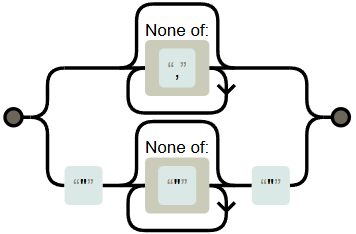
非貪欲マッチ
awkの正規表現は非貪欲マッチをサポートしていない。そのため [^,]*|\".*?\" の代わりに [^,]*|\"[^\"]*\" としている。
そこで2つ連続する二重引用符をフィールドの値として許容するようにFPATを変更する。
awk -v FPAT='[^,]*|\"([^\"]|\"\")*\"' '{for(i=1;i<=NF;++i){printf "%d:%20-s", i, $i} printf "\n"}' csverror.txt
(out)1:"csv,test" 2:csv 3:test
(out)1:"""csv"",""test""" 2:csv 3:"test"
(out)1:csvtest 2: 3:csvtest
この正規表現はCSVのフィールドの全てのパターンを網羅していない。そのためデータによってはこれでもエラーになる。データに合わせて工夫をすればawkで扱えるかもしれないが、高度な内容であればCSVを専門に扱えるツールを利用することを検討した方が良い。
ヘッダ行を飛ばす
データにヘッダ行が含まれていて、1行目だけ処理したくないことがある。いくつか方法が考えられる。自分の環境では速度差はほとんど無かったので、わかりやすいものを選べば良いだろう。
- パターンで1レコード目以外を条件として指定する
FNR!=1 { action }
- パターンで2レコード目以降を条件として指定する
FNR>1 { action }FNR>=2 { action }FNR==2,0 { action }
- 1行目なら次のレコードへ移る処理を指定する
FNR==1 { next }; { action }FNR==1,1{ next }; { action }{if(FNR==1){ next } action }
列の追加
アクションでレコードを書き換えても良い。次の4行4列の数字データについて、各行の合計値に基づいて処理を行いたいとしよう。
| 1 | 2 | 1 | 5 |
| 8 | 2 | 4 | 6 |
| 1 | 4 | 2 | 5 |
| 3 | 7 | 6 | 9 |
存在しないフィールド$5に合計値を代入する。つまり合計値というフィールドを5番目に追加してしまう。次の処理ルールでは$5が20より大きいときに合計値を含めたレコード全体を出力するためにprint $0としている。このプログラムは期待通り正しく動作する。レコード全体に追加したフィールド$5が含まれていることが分かる。
{
print
$5 = $1+$2+$3+$4
print "total:" $5
}
$5>20 {
print "over20",$0
}
awk -f command.awk 4x4number.txt
(out)1 2 1 5
(out)total:9
(out)8 2 4 6
(out)total:20
(out)1 4 2 5
(out)total:12
(out)3 7 6 9
(out)total:25
(out)over20 3 7 6 9 25
$(数字)へ代入が行われると、レコードが更新され、それに伴いNF(フィールド数)なども更新される。あくまで代入されたときのみであり、参照では更新されない。
ダミーデータの生成
入力データを与えないで、なんらかのテストで使うためのCSVデータを生成することもできる。
BEGIN {
if(number == 0){
number = 1000000
}
srand()
for(i=1;i<=number;++i){
value1 = i
value2 = "ABC" int(number*rand())
value3 = int(1000*rand())
value4 = number-i
print value1, value2, value3, value4
}
}
awk -f genRecord.awk -v number="1000000" -v OFS="," > data.csv
less data.csv
(out)1,ABC398203,99,999999
(out)2,ABC187966,973,999998
(out)3,ABC73386,630,999997
(out)4,ABC624966,334,999996
(out)(省略)
strftimeと組み合わせれば時系列順のログを模したダミーデータも作れる。
BEGIN {
maxvalue = number == 0 ? 1000000 : number
unixtime = start == 0 ? systime() : start
if( step <= 2 ){ step = 2 }
srand()
for(i=1;i<=maxvalue;++i){
unixtime += int(step*rand())
value1 = strftime("%Y-%m-%d %H:%M:%S", unixtime)
value2 = "ABC" int(number*rand())
value3 = int(1000*rand())
value4 = i
print value1, value2, value3, value4
}
}
awk -f genRecordTime.awk -v number=100 -v start=1725721200 -v OFS=,
(out)2024-09-08 00:00:03,ABC20,644,1
(out)2024-09-08 00:00:05,ABC85,474,2
(out)2024-09-08 00:00:08,ABC9,504,3
(out)2024-09-08 00:00:11,ABC97,497,4
(out)2024-09-08 00:00:12,ABC34,508,5
(out)(省略)
