Pythonでウェブスクレイピング
ウェブサイトから情報を自動的に抽出、加工するような技術をウェブスクレイピングという。ここではPythonとSeleniumを使用してウェブスクレイピングを実現する方法をまとめる。なお本稿はXPathやCSSセレクタ、Python、HTMLなどの知識をある程度有していることが前提となっている。
はじめに
Seleniumはブラウザー操作を自動化するライブラリ群である。その中核であるWebDriverは様々なブラウザを自動操作するためのインタフェースを提供している。ブラウザとしてChromeを自動操作したいなら、ChromeのWebDriverであるChromeDriverを介してブラウザー操作を行う。
本稿は2023年12月時点の情報を元に記載しており、Python3.12、Selenium(Python版) 4.14、Chromeの組み合わせで動作を確認しています。
インストール
Seleniumは複数言語での実装があり、PythonではPython版Seleniumを使うことになる。pipでインストールできる。
py -m pip install selenium
またWebDriverのインストールも必要である。WebDriverはブラウザごとに用意されており、Chromeの場合はChromeDriverをインストールする。以下のリンク先に記載がある。
https://googlechromelabs.github.io/chrome-for-testing/
WebDriverはブラウザのバージョンによっても変わるため、ブラウザのバージョンと一致しているWebDriverをインストールしなければならない。一致していない場合は実行時に自動操作をするためのセッションが確立できずエラーになる。
Exception has occurred: SessionNotCreatedException
Message: session not created: This version of ChromeDriver only supports Chrome version XXX
Current browser version is YYY with binary path C:\Program Files (x86)\Google\Chrome\Application\chrome.exeChromeDriverのインストールはexeファイルを適当なフォルダに配置するだけであるが、環境変数PATHにあるフォルダに置く(またはPATHを通す)こと。
動作テストプログラム
動作テストとして、ブラウザを起動し、googleのホームページを開くだけのプログラムを実行してみる。
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# WebDriverオブジェクトを取得
with webdriver.Chrome() as browser:
# ブラウザのサイズや位置などのオプションを指定
browser.set_window_size(1600,800)
browser.set_window_position(0,0)
wait = WebDriverWait(browser, 10)
# URLへアクセス
browser.get(r"https://www.google.com/")
# すぐ閉じないように時間を待つ
time.sleep(10)
うまく行けば自動制御されているメッセージが付いたブラウザが立ち上がる。うまく行かない場合、WebDriverのバージョンはあっているか、環境変数Pathが通っているかを確認する。
目的の達成までのステップ
Seleniumでは我々が手動でやっている操作を自動で行うことができる。そのためには手動でやっていることを、Seleniumが対応している操作で表さなければならない。Seleniumで行える主な操作を示す。
- ブラウザの起動設定
- ブラウザに対する操作
- ブラウザを起動する
- 指定のURLを開く
- 履歴に従い戻る、進む
- リロードする
- スクロールする
- ウェブページに対する操作
- ある要素をマウスオーバー状態にする
- ある要素を選択する
- ある要素をクリックする
- ある要素にテキストを入力する
- ある要素が利用できるようになるまで待つ
ブラウザの設定と操作
ブラウザ関連の設定はブラウザごとに仕様が異なることがあり、本稿はChromeを対象にしている。
ブラウザの設定
Capabitility
ウェブページに依存しないブラウザ自体の挙動、たとえばユーザエージェント名として何を使うかや、安全でないTLS証明書を受け入れるかどうか、プロキシは何を使用するか、といったものを設定できる。これらの設定方法はWebDriver Capabilitiesという概念で定義されている。設定できる項目には、すべてのブラウザで使用できるstandard capabilities(標準的な機能)と、ブラウザによって異なるextension capabilities(拡張的な機能)の2種類がある。
SeleniumのPython実装ではOptionsクラスでcapabilitiesを指定する。Optionsクラスを作成していくつかの設定を行い、それをもとにブラウザを起動するサンプルを示す。
Selenium3ではOptionsではなくDesired Capabilitiesが使用されていました。
from selenium import webdriver
import pprint
# Chrome用のOptionsクラスを作成
option = webdriver.ChromeOptions()
# standard capabilitiesはアトリビュートで設定できる
option.accept_insecure_certs = True
# extension capabilitiesはset_capacityで設定できる
option.set_capability( "capability", "value" )
# ブラウザの実験的な機能はexperimental_optionで設定できる
option.add_experimental_option( "experimental", "value" )
# ブラウザ実行時の引数も指定できる
option.add_argument( "--headless" )
# 設定されるCapablitiesを出力してみる
capabilities = option.to_capabilities()
pprint.pprint(capabilities)
(out){'acceptInsecureCerts': True,
(out) 'browserName': 'chrome',
(out) 'goog:chromeOptions': {'args': ['--headless'],
(out) 'extensions': [],
(out) 'experimental': 'value'},
(out) 'pageLoadStrategy': 'normal',
(out) 'capability': 'value'}
(out)
# Optionsを指定してブラウザを起動
# ただし本サンプルは使えないcapabilitiesを含むため例外が発生する
# with webdriver.Chrome(options=option) as browser:
# browser.get(r'http://www.yahoo.co.jp/')
主なstandard capabilitiesを示す。
| browserName | ブラウザ名。作成時にデフォルトで設定されている。 |
| pageLoadStrategy | ページ読み込み戦略。URL指定でページ遷移する場合、WebDriverはページとページで使われているリソースの読み込みが完了するまで待機する。JSSや画像が必要でない場合は、読み込み戦略を変えることで動作を変えることができる。 normal:デフォルト。すべてのリソースをダウンロードするまで(Window:loadイベントが発生するまで)ブロックする。JavaScriptなど動的に追加される要素は準備できていない可能性がある。 eager:DOMにアクセスできるようになるまで(Document:DOMContentLoadedイベントが発生するまで)ブロックする。画像などはロード中の可能性がある。 none:ブロックしない。 |
| acceptInsecureCerts | Trueの場合、期限切れまたは無効なTLS証明書を受け入れる。 |
| proxy | プロキシの指定(詳細は次項) |
プロキシの指定
プロキシを指定するサンプルを示す。プロキシを指定するときはOptionsに直接ではなく、capabilitiesに変換する必要があるようだ。なお、これはプロキシを手動設定する例であり、PACファイルを使用するときはタイプをProxyType.PACとしてproxyAutoconfigUrl属性にPACファイルのURLを指定する。
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy,ProxyType
# Chrome用のOptionsクラスで設定し、capabilitiesに変換
option = webdriver.ChromeOptions()
option.accept_insecure_certs = True
capabilities = option.to_capabilities()
# capabilitiesにプロキシ設定を追加
proxy = Proxy()
proxy.proxyType = ProxyType.MANUAL
proxy.httpProxy = r"http://192.168.1.10:8080"
proxy.sslProxy = r"http://192.168.1.10:8080"
proxy.ftpProxy = r"http://192.168.1.10:8080"
proxy.noProxy = r"*.yahoo.co.jp;*.google.com;"
proxy.add_to_capabilities(capabilities)
with webdriver.Chrome(desired_capabilities=capabilities) as browser:
(省略)
Chromeでは実行時の引数でもプロキシを指定できる。この方法は標準化された指定方法ではないため、Chrome以外のブラウザで実行するには修正しなければならない。
from selenium import webdriver
# Chrome用のOptionsクラスで設定し、capabilitiesに変換
option = webdriver.ChromeOptions()
option.add_argument('--proxy-server=http://192.168.1.10:8080/')
with webdriver.Chrome(options=option) as browser:
(省略)
その他の設定
他に使う機会があった設定をいくつか示す。これらはいずれもChromeのみがサポートする設定の可能性がある。
| プロファイルを指定して開く | option.add_argument(r"--user-data-dir=C:\Users\xxxxxx\AppData\Local\Google\Chrome\User Data")プロファイルが保存されているディレクトリとプロファイル名を指定する。そのプロファイルで最後に開いたサイトやブックマーク、拡張機能などが有効になる。 プロファイルが使用されている(ブラウザが起動している場合など)とDevToolsActivePort file doesn't existのようなエラーになるので注意。 |
| サンドボックスを無効にする | option.add_argument("--no-sandbox") |
| GPUアクセラレータを無効にする | option.add_argument("--disable-gpu")仮想環境などでうまく動かないときなど |
| 証明書のエラーページを表示しない | option.add_argument("--ignore-certificate-errors")社内サイトなどで自己署名証明書などの証明書エラーを無視したいときに |
| シークレットモードで起動 | option.add_argument('--incognito')Seleniumは毎回新しいプロファイルを作成して起動しているため、普段のプロファイルをSeleniumで使いたくないという理由ならシークレットモードを使う必要はない |
| ヘッドレスモートで起動 (バックグラウンドで起動) | option.add_argument('--headless')専用のプロパティもあるが非推奨となっている。 # option.headless = True |
ブラウザの操作
WebDriver
WebDriverクラスはブラウザそのものに対して行う操作をサポートする。下表のコマンドはbrowserにWebDriverのインスタンスが格納されている場合のものである。
| ウィンドウ関連 | 大きさ | browser.set_window_size(600,800) | {'width': 600, 'height': 800} |
| 位置 | browser.set_window_position(100,100) | {'height': 1372, 'width': 1705, 'x': 10, 'y': 10} | |
| 大きさと位置 | browser.set_window_rect( 50, 100, 500, 800 ) | {'height': 800, 'width': 516, 'x': 50, 'y': 100} | |
| ナビゲーション関連 | 戻る | browser.back() | |
| 進む | browser.forward() | ||
| 更新 | browser.refresh() | ||
| クッキー関連 | クッキーの追加 | browser.add_cookie( dict )dictにクッキー情報を入れる。name、valueキーが必須。 クッキーのオプションであるdomainやpathなども指定できる。 dictの例は次のクッキーの取得の項目を参照すること。 | |
| クッキーの取得 | browser.get_cookie("name") | { 'domain': '.example.com', 'expiry': 1723381520, 'httpOnly': True, 'name': 'A', 'path': '/','sameSite': 'Lax', 'secure': True, 'value': 'abc'} | |
| クッキーの削除 | browser.delete_cookie("name") | ||
| ページ関連 | タイトルの取得 | browser.title | |
| URLの取得 | browser.current_url | ||
| その他 | 操作の終了 | browser.quit()※WebDriverはPythonのコンテキストマネージャでありwithが使用できる |
コンテキストの切り替え
他のタブやウィンドウ、あるいはページにあるFrame内部の操作を行うような場合はコンテキストを切り替える。なおSeleniumではタブとウィンドウは基本的に区別されない。
| コンテキスト関連 | コンテキストの切り替え | browser.switch_to.<target>(...) | ※targetには切り替え先が入る フレームなら browser.switch_to.frame( ... )ウィンドウなら browser.switch_to.window( ... ) |
| デフォルトのコンテキストに戻る | browser.switch_to.default_content() |
待機
ブラウザ操作を自動化するときに待つことはとても重要となる。Webページの読み込みに時間がかかることもあるだろうし、利用条件の同意ボタンがクリックできるようになるまで10秒待たされることもあるだろう。SeleniumではWebDriverWaitクラスで待機することができる。
基本概念
WebDriverWaitクラスは指定された状態になるまでポーリングを行い、時間内にその状態になれば終了する。時間内にその状態にならなかった場合はタイムアウトとなり例外が発生する。以下は条件を満たしているか1秒毎にチェックし、最大で10秒待機するWaitである。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
with webdriver.Chrome() as browser:
wait = WebDriverWait(browser, timeout=10, poll_frequency=1)
browser.get(r'https://www.google.com/')
wait.until( SOME_CONDITION )
wait.untilメソッドのSOME_CONDITIONには条件が満たされたときにTrueを返す関数を入れる。
条件のヘルパー
よく使われる条件がexpected_conditionとして提供されている。from selenium.webdriver.support import expected_conditionsで利用できる。
本項では from selenium.webdriver.support import expected_conditions as Conditionとして、expected_conditionsに対してConditionという別名をつけている。
要素の状態を評価する
要素がクリックできる、見える状態にあるなど特定の状態を満たしているか判定する関数を示す。どの要素を確認するかは引数で指定する。あらかじめ取得したWebElementオブジェクト(表ではelement)を渡すか、要素の場所を示すロケータ(表ではlocator)を渡す。ロケータの詳細は要素の選択の節に記載する。
| 求める条件 | 関数 | DOMに存在 | 可視 | クリック可能 |
|---|---|---|---|---|
| クリックできる | Condition.element_to_be_clickable( element | locator ) | YES | YES | YES |
| 可視である | Condition.visibility_of_element_located( element | locator ) | YES | YES | - |
| 存在する | Condition.presence_of_element_located( element | locator) | YES | - | - |
| 存在しない、または可視でない | Condition.invisibility_of_element( element | locator ) | NOR | NOR | - |
| 存在しない | Condition.staleness_of( element ) | NO | - | - |
たとえば、element_to_be_clickableであれば要素がクリックできる状態になるまで待機することになる。
これらの関数は条件が満たされたときに、条件を満たした要素WebElementを返す。また、wait.untilメソッドは引数の関数が返した戻り値をそのまま返す。そのため、以下のような実装で、指定された条件が満たされるのを待ちつつ、条件を満たした要素を取得できる。
element = wait.until(Condition.visibility_of_element_located((By.XPATH, r'//*[@id="header"]')))
このコードはXPATHで//*[@id="header"]という要素が可視になるまで待機し、可視となった要素を取得する。
URLやタイトルの状態
| 求める条件 | 関数 |
|---|---|
| URLが完全一致 | Condition.url_to_be( url ) |
| URLが正規表現に一致 | Condition.url_matches( pattern ) |
| URLに指定文字列が含まれる | Condition.url_contains( string ) |
| タイトルが完全一致 | Condition.title_is( title ) |
| タイトルに指定文字列が含まれる | Condition.title_contains( string ) |
複合条件
| 求める条件 | 関数 |
|---|---|
| すべてのexpected_conditionが満たされる(論理積) | Condition.all_of( *expexted_conditions ) |
| 少なくとも1つのexpected_conditionが満たされる(論理和) | Condition.any_of( *expexted_conditions ) |
| いずれのexpected_conditionも満たされない(否定論理和) | Condition.none_of( *expected_conditions ) |
要素の選択
ページ上の要素を取得するにはWebDriverのfind_elementかfind_elementsを使う。これらのメソッドは、指定した条件に一致する要素を取得する。find_elementはDOMツリー上で最初に一致した要素を返し、find_elementsは一致した要素をすべて返す。戻り値はそれぞれWebElement、list[WebElement]である。なお、要素が見つからなかった場合にfind_elementはNoSuchElementExceptionが発生するのに対し、find_elementsは例外を発生させず空のリストを返すという違いもある。
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.by import By
with webdriver.Chrome() as browser:
browser.get(r'https://www.google.com/')
element:WebElement = browser.find_element( By.TAG_NAME, "textarea")
なお、待機の節に記載の通り、WaitとExpected Conditionを組み合わせることでも要素を取得できる。Waitと併用する方法は、動的に追加される要素やページの読み込み直後など、その時点で要素が存在するか不確定だが、時間が経てば存在することが期待される場合はこちらが適切である。
element = wait.until(Condition.visibility_of_element_located((By.XPATH, r'//*[@id="header"]')))
要素の選択方法は8種類あるが、個人的によく使う6種類を上げておく。
| 指定方法 | 意味 | 指定方法 | 意味 |
|---|---|---|---|
| By.ID | id属性 | By.NAME | name属性 |
| By.CSS_SELECTOR | CSSセレクタ | By.XPATH | XPATH |
| By.LINK_TEXT | リンクの文字列 | By.PARTIAL_LINK_TEXT | リンク文字(部分一致) |
たとえばCSSセレクタでdiv > h3を満たす要素を取得したい場合、browser.find_element(By.CSS_SELECTOR, "div > h3")のようにする。この要素の指定方法、あるいは指定方法とその値の組み合わせのことをlocator(ロケータ)と呼ぶ。
Seleniumの関数の中には引数にElementとlocatorの両方に対応しているメソッドがある。
# locatorを渡す
expected_condition.element_to_be_clickable( (By.TAG_NAME, "button") )
# elementを渡す
element = browser.find_element( By.TAG_NAME, "button")
expected_condition.element_to_be_clickable( element )
CSSセレクタ
CSSセレクタはCSSでスタイルを適用する要素を指定するときに使う記法である。本稿はCSSセレクタを説明することを目的としておらず、筆者がよく使うものを記載している。
基本のセレクタ
| セレクタ | 意味 | セレクタ | 意味 |
|---|---|---|---|
| E | Eという名前の要素 | #ID | 指定のIDを持つ要素 |
| .CLASS | 指定のクラスを持つ要素 | * | すべての要素 |
| [attr=value] | 属性セレクタ | :is(selector1, selector2, ....) | ()内のいずれか |
上下関係のセレクタ
| セレクタ | 意味 | セレクタ | 意味 |
|---|---|---|---|
| E F | Eより下の階層にあるF(子孫関係) | E > F | Eの1つ下の階層にあるF(親子関係) |
| E + F | Eと同じ階層にあるF(隣接関係) | E ~ F | Eと同じ階層で、後ろにあるF |
組み合わせの例
E#content F.title.border + :is(G, H) > .haveの場合、以下のような解釈となる。
E#content | IDがcontentのE要素 |
␣ (半角スペース) | より下の階層にある |
F.title.border | titleとborderクラスを持つF要素 |
+ | と同じ階層にある |
:is(G, H) | G要素 か H要素 |
> | の1つ下の階層にある |
.have | haveクラスを持つ要素 |
位置関係の指定
| セレクタ | 意味 | セレクタ | 意味 |
|---|---|---|---|
| X:first-child | 条件を満たすX要素の中で最初に登場するもの | X:last-child | 条件を満たすX要素の中で最後に登場するもの |
| X:nth-child( 指定位置 ) | 条件を満たすX要素の中で指定番目に登場するもの。 指定位置を数字で指定した場合、その番号で登場するものになる。例えば5なら5番目に登場するX要素である。 整数を意味するnを使って指定することもできる。たとえば2nなら偶数番目、2n+1なら奇数番目、5nなら5個ごとのような指定である。 |
発展的なセレクタ
| セレクタ | 意味 | セレクタ | 意味 |
|---|---|---|---|
| :not( selector ) | 否定 | :has( selector ) | 子孫にselectorを持つ |
これらを組み合わせることで複雑な指定が可能になる。
XPath
XPathはXML文書の中にある特定の要素や属性値を指定する記法である。(厳密にはHTMLはXMLではないが、XPathで要素を取り出すことはできる。)本稿はXPathを説明することを目的としておらず、私がよく使うものを記載するだけに留める。
基本
XPathではXML文書の階層構造をルートを起点として「/要素1/要素2/要素3/」のように表す。たとえば/a//b/text()なら「ルート直下のa要素の配下にあるb要素のテキストノード」を意味する。
| 基本 | 意味 | 記法 | 意味 |
|---|---|---|---|
| / | 直下 | // | 配下(パスの省略) |
| E | 要素名が一致する要素 | * | すべての要素 |
| .. | 親要素 | text() | テキストノード(要素内のテキスト) |
述部
E[...]のように要素名に角括弧をつけると、「...の条件を満たすE」という意味になる。これを述部という。述部の中の条件はandやorで複数指定できる。
| 基本 | 意味 | 基本 | 意味 |
|---|---|---|---|
| E[F ] | Fを子要素に持つE | E[ text()="value" ] | 要素内のテキストがvalueであるE |
| E[ @attr='value' ] | attr属性の値がvalueであるE | E[contains(@attr,'value')] | attr属性の値がvalueを含むE |
| E[ @attr ] | attr属性を持つE | E[ n ] または E[ position()=n ] | n番目のE要素 |
| E[ first() ] | 最初のE要素 | E[ last() ] | 最後のE要素 |
X=Yと書いてあるものは完全一致となり、starts-with(X,Y)、ends-with(X,Y)、contains(X,Y)に置き換えることで部分一致などで指定できる。数字であるなら>、<などの不等号も使える。なお、Eの部分は特定の要素名ではなく*でもよい。
関数
XPathでは述部などで関数が使用でき、簡単な文字列演算や数値演算が行える。前述のcontainsなども関数の一つである。
テキスト関連の関数
| 関数 | 意味 | 関数 | 意味 |
|---|---|---|---|
| contains( str1, str2 ) | str1にstr2が含まれれば条件を満たす | normalize-space( str ) | strの空白を正規化する |
| starts-with( str1, str2 ) | str1がstr2で始まれば条件を満たす | translate( str, char_list1, char_list2) | 文字単位で置換する |
| substring( str, start, [length] ) | 部分文字列を抽出する(1始まり) | substring-before( str1, str2 ) substring-after( str1, str2 ) | str1のstr2より前/後の部分を抽出する |
数値関連の関数
| 関数 | 意味 | 関数 | 意味 |
|---|---|---|---|
| count( nodes ) | 要素の個数を数える | ||
| position() | コンテキストにおける要素の位置を返す | last() | コンテキストにおける要素数を返す |
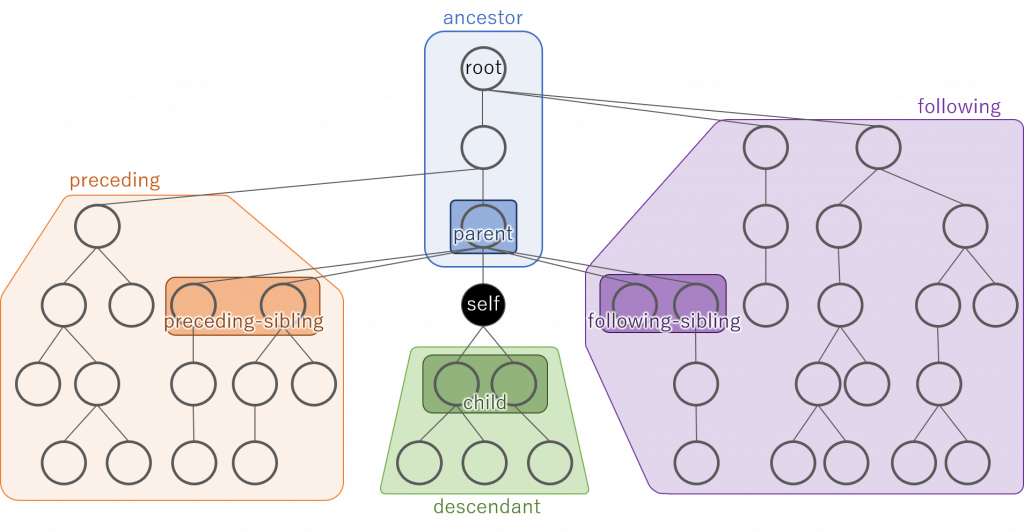
軸
XPathではルート以外の位置からみた相対的な位置関係で要素を指定できる。たとえば//E/ancestor::Fは、「ルートの配下にあるE要素から見て、祖先であるF要素」という意味になる。この相対的な位置関係による指定方法を軸といい、柔軟に要素選択を可能にする記法である。軸は2つのコロン::で記す。
以下に軸で指定可能な値とそのイメージ図を示す。
| axes | 意味 | axes | 意味 |
|---|---|---|---|
| ancestor | 祖先 | ancestor-or-self | 祖先 および 自身 |
| parent | 親 | - | - |
| self | 自身 | - | - |
| child | 子 | - | - |
| descendant | 子孫 | descendant-or-self | 子孫 および 自身 |
| 以下は前後関係 | |||
| preceding | XML文書中の登場順序が前であり、かつ祖先でないもの | preceding-sibling | precedingのうち親が同じもの |
| following | XML文書中の登場順序が後であり、かつ子孫でないもの | following-sibling | followingのうち親が同じもの |
要素の操作
要素が選択できれば、その要素の情報を取得したり、クリックしたりできる。ここではelementに要素が取得できているものとする。
| 操作 | プロパティ・メソッド |
|---|---|
| 要素名の取得 | element.tag_name |
| 属性の取得 | element.get_attribute("属性名") |
| コンテンツテキストの取得 | element.text |
| 各状態の取得 | 要素が表示されているか(hiddenではないか)element.is_displayed()要素が有効か(disabledではないか) element.is_enabled()ラジオボタンなどのユーザが選択可能な要素において、要素が選択されているか(checked=trueか) element.is_selected() |
| 要素の位置や大きさを取得 | 要素の位置element.location要素の矩形(位置情報、幅、高さ) element.rect |
| CSSの値を取得 | element.value_of_css_property("取得したいCSSプロパティ") |
| 親要素の取得 | element.parent |
| 子要素の検索 | element.find_element(検索方法,"検索する子要素")element.finds_element(検索方法,"検索する子要素") |
| 操作 | プロパティ・メソッド |
|---|---|
| クリック | element.click() |
| タイピング | element.send_keys( "text" ) |
| (テキストボックス要素において)入力テキストのクリア | element.clear() |
Enterや矢印キーなどの特殊キーはKeysに定義されている定数を使う。また一部記号もKeysに用意されている。
from selenium.webdriver.common.keys import Keys
( 省略 )
element.send_keys( Keys.CONTROL, "a" ) # これはCtrl-Aに等しい
| Deleteキー | Keys.DELETE | BackSpaceキー | Keys.BACKSPACE |
| 上キー | Keys.ARROW_UP | 下キー | Keys.ARROW_DOWN |
| 左キー | Keys.ARROW_LEFT | 右キー | Keys.ARROW_RIGHT |
| Ctrlキー | Keys.CONTROL | Altキー | Keys.ALT |
| エンター | Keys.RETURN | ファンクションキー | Keys.F1 ~ Keys.F12 |
| タブ | Keys.TAB |
select要素専用の操作
HTMLのselect要素むけに特別なユーティリティクラスが用意されている。
from selenium.webdriver.support.select import Select
( 省略 )
select = Select( element ) #elementはselect要素
| 操作 | 関数 |
|---|---|
| 選択肢リストの取得 | select = Select( element ) #elementはselect要素のWebElementインスタンス |
| 選択されている選択肢の取得 | select.all_selected_options |
| 選択する | select.select_by_visible_text( "選択肢" ) |
| 選択を外す | select.deselect_by_visible_text( "選択肢" ) |
| すべての選択を外す | select.deselect_all() |
ActionChains
WebDriverやWebElementに用意されているメソッドでは行いたい操作が実現できない場合、より低レベルなAPIであるActionChainsで解決できるかもしれない。ActionChainsはその名の通り、行いたい操作を.でつなげていくイメージになる。最後にperform()で操作が実行される。
from selenium.webdriver import ActionChains
( 省略 )
act = ActionChains(browser)
act.click_and_hold().move_by_offset(20,20).release().perform()
これはマウスドラッグのActionChainsのサンプルである。ActionChainsでは右クリックやドラッグなどが行えるが詳細は公式ドキュメントを参照すること。
スクリプトの実行
SeleniumからJavaScriptを実行させることができる。JavaScript内でreturnしたものを結果として受け取れる。
result = browser.execute_script("javascript code")
結果の記録
スクリーンショット
作業自動化などでSeleniumを使う場合、作業記録としてスクショを撮りたいことがある。Seleniumにはスクリーンショットを撮る関数が用意されている。以下はブラウザの画面全体のスクショを撮る例だが、element.screenshot()で特定の要素だけのスクショを撮ることも可能だ。ちなみにファイル出力ではなくバイト列で取得するメソッドもある。
browser.save_screenshot('c:\path\to\file.png')
このbrowser.screenshotメソッドはブラウザ上で表示されている範囲しか記録されない。特に縦長のサイトではすべてを記録できない。対応方法の1つとしてブラウザの大きさをウェブページの大きさに合わせてしまうことがある。通常のChromeはディスプレイの大きさの制限を受けるため、ヘッドレスモードで制限を回避する。
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
option = Options()
option.add_argument('--headless')
with webdriver.Chrome(options=option) as browser:
browser.get(r'https://www.yahoo.co.jp/')
# ブラウザの大きさをbody要素の大きさに合わせてからスクショ
element:WebElement = browser.find_element(By.XPATH, r'//body')
browser.set_window_size(element.size['width'], element.size['height'])
browser.save_screenshot('test.png')
この方法のデメリットはヘッドレスモードであることそのものだ。完全自動化で結果だけ見れればそれでいいなら問題ないが、半自動化や定期的な経過観察が必要なときには使えない。そうなると、ページをスクロールしながらスクショを取り、結合して1枚のスクショを作成することになるだろう。ただしそれはそれでスクロールに応じて動的に読み込むページであったり、スクロールに追従しない要素があったときにスクリーンショットがおかしくなるという弊害も生まれる。
一応動作したスクロールしながらスクショをとるプログラムを示す。ただし、このプログラムはX横方向にスクロールがでることは考慮していないし、私は画像ライブラリを普段使わないため大間違いをしている可能性がある。
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from PIL import Image
option = Options()
option.add_argument('--hide-scrollbars')
with webdriver.Chrome(options=option) as browser:
browser.set_window_size(1200,800)
browser.get(r'https://www.yahoo.co.jp/')
element:WebElement = browser.find_element(By.XPATH, r'//body')
# 各種サイズを取得
# windowsize:ブラウザのサイズ、bodysize:body要素(キャプチャ対象)のサイズ、screensize:スクショのサイズ
_tmpsize = browser.get_window_size()
windowsize = (_tmpsize['width'], _tmpsize['height'] )
bodysize = (element.size['width'], element.size['height'])
browser.save_screenshot("temp.png")
with Image.open("temp.png") as img:
screensize = img.size
# サイズアクセス用の定数
X = 0; Y = 1
# 継ぎ接ぎ用のキャンバス
canvas = Image.new('RGBA', (screensize[X], bodysize[Y]))
offset = [0, 0]
while True:
# スクロールしてからスクショを取る
# Seleniumにスクロール機能はないためJavaScriptで実装
browser.execute_script(f'window.scrollTo({offset})')
browser.save_screenshot("temp.png")
# このスクショが最後の一枚かどうかで処理が異なる。
# ・最後の一枚でないなら単純にキャンバスに張り付け
# ・最後の一枚の場合は、直前の一枚と重複しているところをカットしてキャンバスに貼り付ける
if offset[Y] + screensize[Y] < bodysize[Y]:
with Image.open("temp.png") as img:
canvas.paste( img, offset.copy() )
else:
# 最後の一枚の場合の処理
# 必要なサイズのtmpcanvasにペーストすることで直前の一枚と重複しているところを取り除く
tmpcanvas = Image.new('RGBA', (screensize[X], bodysize[Y]-offset[Y]))
with Image.open("temp.png") as img:
tmpcanvas.paste( img, ( 0, -(screensize[Y]-tmpcanvas.size[Y]) ) )
canvas.paste(tmpcanvas, offset.copy())
break
offset[Y] = offset[Y] + screensize[Y]
canvas.save("temp.png")
個人用備忘録など
サンプル
Googleのトップページにアクセスし、右上のメニューからニュースページにアクセスする。IFrameが使われているためコンテキストの切り替えが必要。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as Condition
from selenium.webdriver.common.by import By
with webdriver.Chrome() as browser:
wait = WebDriverWait(browser, 20)
browser.get(r'https://www.google.com/')
# 右上のメニューをクリック
wait.until(Condition.element_to_be_clickable((By.XPATH, r"//a[@aria-label='Google アプリ']"))).click()
# メニュークリックで開いたアプリの一覧画面(IFrame)にコンテキストをスイッチ
_ = browser.find_element(By.XPATH, r"//iframe[@name='app']")
wait.until(Condition.visibility_of(_))
browser.switch_to.frame(_)
# IFrameの中でニュースというテキストをもつA要素をクリック
browser.find_element(By.XPATH, r"//*[contains(text(), 'ニュース')]/ancestor::a").click()
browser.switch_to.default_content()
time.sleep(10)
よく使うimport文
Seleniumは階層が複雑なため、毎回何をインポートする必要があるか忘れるためよく使うものを残しておく。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as Condition
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
from selenium.webdriver import ActionChains
要素の選択方法
自身が管理していないサイトの情報を取得する場合、サイトの更新により要素が取得できなくなってしまうことがある。そこでロケータをいかに柔軟な指定にするかが維持管理を楽にする上で重要となる。ルートから階層構造を指定したXPathを指定すれば確実に要素を取得できるが、サイトのほんの僅かな更新でも取得できなくなるリスクが高くなる。一方で要素は特定できるものの柔軟な記載にしておくとサイトの多少の更新であれば動作を継続できる。
画像読み込みの待機
画像だけを取得したい場合があり、imgタグを探してそのsrc属性から画像のURLを取得して、そのURLをダウンロードする形で実装した。ウェブ上に例が多数あり、画像を2回ダウンロードするという無駄はあるが、シンプルに実装できる。
import urllib3
(省略)
_ = browser.find_element(By.XPATH, r'//img')
imgurl = _.get_attribute("src")
http = urllib3.PoolManager()
response = http.request("GET", imgurl)
しかし、画像は表示されているのに、URLではダウンロードできない事象が発生し、手っ取り早い手法としてスクショをとることにした。
import base64
from io import BytesIO
(省略)
_ = browser.find_element(By.XPATH, r'//img')
_ = _.screenshot_as_base64
image = Image.open(BytesIO(base64.b64decode(_)))
さらに、サーバが重いときに画像を読み込み途中のスクショになることがあったため、画像の読み込みが完了しているかチェックする処理を追加することで対応した。画像読み込みの完了確認機能はSeleniumにはないためJavaScriptで実現している。
for _ in range(20):
imgloaded = browser.execute_script("""\
var image = document.evaluate('//img',document,null,XPathResult.ANY_TYPE,null);\
return image.iterateNext().complete;\
""")
if imgloaded:
break
time.sleep(1)
else:
raise TimeoutError()
補足するとbrowser.get(url)でURLを遷移したときは、デフォルトでページのすべてのリソースが読み込まれるのを待機する(pageLoadStrategy参照)。しかし動的に読み込まれるリソースなど一部はそうならない。
