sedコマンド
sedの特徴
sedはStream EDitorであり、入力ストリームから流れてくるテキストをスクリプトを使って編集するツールである。
Fizz
Buzz
FizzBuzz
FizzBuzzBuzzこのテキストを入力として、BuzzをFizzに置換するsedスクリプトを実行する。
sed '2,3s/Buzz/Fizz/' sample.txt
(out)Fizz
(out)Fizz
(out)FizzFizz
(out)FizzBuzzBuzz
'2,3s/Buzz/Fizz/'がsedの動作を指定するスクリプトである。このスクリプトは最初の2,3が「2行目から3行目」、次のsが「置換処理(Substitute)を行う」、残りの/Buzz/Fizz/が「BuzzをFizzに」という意味を持っている。
sedは以下のようにコマンドを実行する。
- 入力ストリームから1行読み込み、改行を取り除いたものをパターンスペースと呼ばれるバッファに記憶する。
- 処理条件を満たしているか検査し、満たしていた場合はコマンドを実行する。
- スクリプトの終端に達した場合、1.に戻り次の入力行に対して処理を行う。
- このとき、既定でパターンスペースの内容を出力ストリームへ出力する。
- 1.で改行を取り除いた場合、改行を追加して出力する。
-nオプションを付けた場合は出力しない(コマンドで明示的に出力指示があったものは除く)
このように、sedは行単位でテキストを読み込み、スクリプトに従って編集を行えるツールである。
スクリプト
sedの肝はなんと言ってもスクリプトである。スクリプトの構文は以下のようになっている。
[address]X[option]
| [address] | コマンドを実行する対象を示すもの 省略した場合は全ての行 |
| X | 実行するコマンド |
| [option] | コマンドに応じたオプション |
複数のスクリプト
複数のスクリプトを指定するときは-eオプションを使うか、セミコロンで区切って書く。
sed -e '2,3s/Buzz/Fizz/' -e '2s/Fizz/Buzz/' sample.txt
(out)Fizz
(out)Buzz
(out)FizzFizz
(out)FizzBuzzBuzz
sed '2,3s/Buzz/Fizz/; 2s/Fizz/Buzz/' sample.txt
(out)Fizz
(out)Buzz
(out)FizzFizz
(out)FizzBuzzBuzz
1つのアドレスに対して複数のコマンドを実行するときは{}で囲み、セミコロンか改行で区切る。
sed '2,3{s/Buzz/Fizz/; i\
(con)Hello!
(con)}' sample.txt
(out)Fizz
(out)Hello!
(out)Fizz
(out)Hello!
(out)FizzFizz
(out)FizzBuzzBuzz
ファイルからスクリプトを読み込む
fオプションを使ってスクリプトが書かれたファイルを読み込める。
sed -f sedscript.txt sample.txt
アドレス
アドレスとはsedがどの行を処理するか指し示すものである。処理条件と考えれば良い。アドレスが指定されない場合はすべての行に対して処理を行う。
行番号で指定する
処理対象を何行目かで指定するには、アドレスとして行数を書く。最終行を意味する特別な記号として$が利用できる。
| 144X | 144行目にXというコマンドを実行 |
| $X | 最終行にXというコマンドを実行 |
start~stepを使用すると、「step行ごと」という指定ができる。数式で表せばstart~stepは\textrm{start} + \textrm{step}\,n \quad(\textrm{nは0以上の整数})となる。[GNU sed]
| 5~3X | 5行目から3行ごとにXというコマンドを実行 5+3n行目 (5行目、8行目、11行目、14行目、...) |
| 0~2X | 偶数行でXというコマンドを実行 0+2n行目 (0行目、2行目、4行目、6行目、...) |
| 1~2X | 奇数行でXというコマンドを実行 1+2n行目 (1行目、3行目、5行目、7行目、...) |
正規表現で指定する
入力テキストがパターンにマッチするかで処理対象を指定できる。
| /regexp/ | 正規表現regexpに一致した行 |
| \@regexp@ | 正規表現regexpに一致した行 (@は他の文字でもよい) |
正規表現の処理を指定するオプションI、Mを付与できる。
| /regexp/I \@regexp@I | 大文字小文字を区別しないで正規表現regexpに一致した行 |
| /regexp/M \@regexp@M | マルチラインモードで正規表現regexpに一致した行 |
処理範囲を指定する
,を使うと行の範囲を指定できる。
| 10,32 | 10行目から32行目まで |
| 5,$ | 5行目から最終行まで |
| /regexp1/,/regexp2/ | 正規表現regexp1に一致した行から、regexp2に一致する行まで |
| 20,/regexp/ | 20行目から、正規表現regexpに一致する行まで |
GNU拡張の指定
| address,+N | adressに一致した行と、その後に続くN行 |
| address,~N | adressに一致した行から、Nの整数倍の行まで 例:20,~8 の場合、20、21、22、23、24(8*3)が処理対象となる |
アドレスの否定
!を付けるとアドレス指定が反転する。例えば4!は「4行目でないとき」、3,5!は「3行目から5行目でないとき」を意味する。
複数ファイルを処理するときのアドレス
sedは複数ファイルの入力も1つのストリームとして処理するのがデフォルトである。複数ファイルを処理するときのアドレス指定の注意点を示す。
| 項目 | デフォルトの動作 | -iまたは-sを付けたときの動作 |
|---|---|---|
| 行番号 | 複数のファイルにまたがって、連続して数える。 | ファイルごとに数える。 |
| $の位置 | 最後のファイルの最終行 | 各ファイルの最終行 |
| 範囲指定の終端 | ファイルの末尾に達しても範囲は終了しない。ファイルをまたがって範囲が継続する。 | ファイルの末尾に達したら範囲が終了する。 |
ファイルをまたがるアドレス
実際にアドレス範囲がファイルをまたぐ例を示す。
| ファイル名 | abc.txt | 123.txt |
|---|---|---|
| ファイルの内容 | a b c | 1 2 3 |
sed '/b/,/2/a\
(con) !
(con)$a\
(con)=== $ ===
(con)' abc.txt 123.txt
(out)a
(out)b
(out) !
(out)c
(out) !
(out)1
(out) !
(out)2
(out) !
(out)3
(out)=== $ ===
sed -s '/b/,/2/a\
(con) !
(con)$a\
(con)=== $ ===
(con)' abc.txt 123.txt
(out)a
(out)b
(out) !
(out)c
(out) !
(out)=== $ ===
(out)1
(out)2
(out)3
(out)=== $ ===
この2つのコマンドは、bを含む行から2を含む行までがアドレスとなっている。1つ目のコマンドはデフォルトの挙動であり、abc.txtの2行目からファイルをまたがって123.txtの2行目までが実行されている。2つ目のコマンドは-s(separate)オプションによりファイルごとに動作するモードになり、abc.txtの2行目からabc.txtの終端までが実行される。
コマンド
置換(Substitute)
s/正規表現/置換後の文字列/フラグ
置換するにはsに続けて正規表現と置換後の文字列を指定する。置換後の文字列では\n(nは1~9)で前方参照が行える。
sに続く文字
sに続く/を正規表現や置換後の文字列に含めたい場合、コマンドの/を別の文字に置き換えても良い。たとえば、s@正規表現@置換後の文字列@フラグは正しいコマンド指定である。このsに続く文字を正規表現や置換に含めるときは\でエスケープする。
GNU sedでは以下の拡張フラグを使用して、大文字小文字を変換できる。
| 次の文字を大文字/小文字にする | 大文字:\u小文字: \l | \u\1の場合、\uの影響を受けるのは\1の1文字目だけである。もし\1がabcであれば結果はAbcとなる。 |
| 次の文字以降を大文字/小文字にする | 大文字:\U小文字: \L | \Eで変換の終了位置を指定する。\U\1\Eとすると\1の文字が全て大文字になる。また \U\1\L\2\E\3のように、反対の指定がされた場合も終了する。つまりこれは\U\1\E \L\2\E \3とみなされ\3には大文字/小文字の変換は適用されない。 |
拡張正規表現
sedはデフォルトでは標準正規表現(BRE)であり、Eオプションsed -Eを付けると拡張正規表現となる。
| 特徴 | BRE | ERE |
|---|---|---|
| 文字として扱う場合に エスケープが必要な特殊文字 | ^ $ \ . [ ] * | ^ $ \ . [ ] * + ? { } ( ) | |
| グループ化 | \( ... \) | ( ... ) |
| オルタネーション | なし | | |
| 0回または1回の出現 | \? | ? |
| 1回以上の出現 | \+ | + |
| 繰り返し回数の指定 | \{m,n\} | {m,n} |
フラグ
| g | 最初に一致したテキストではなく、一致した全てのテキストを置換する。 |
| n ※数値 | n番目に一致したテキストを置換する。 |
| p | 置換したとき、置換後のテキストを出力する。 |
| w ファイル名 | 置換したとき、置換後のテキストをファイルに出力する。 |
| e | 置換したとき、置換後のテキストをシェルコマンドとして実行する。[GNU拡張] |
| I i | 大文字小文字を区別しない |
| M m | 複数行モードの正規表現マッチを行う。 |
削除(Delete)
d
パターンスペースを削除する。後続のコマンドがある場合、それらはスキップされ、すぐに次の行の処理へ移る。
出力(Print)
p
パターンスペースをただちに出力する。
次の行へ移る(Next)
n
次の行へ移る。このとき、デフォルトの挙動ではパターンスペースが出力される。
挿入(Insert)
i\
Text
GNU拡張記法:
i Text
すぐにiに続く文字を出力する。この文字はエスケープ処理が行われる。
追加(Append)
a\
TEXT
GNU拡張記法:
a TEXT
行の後に追加する。このコマンドはaに続く文字をキューに入れる。現在のパターンスペースの処理が終わると、キューの内容が出力される。
aとiの実行例
iとaの処理タイミングの違いが分かる例を示す。
(out)$ sed -e "i ---" -e "/Buzz/a There's a Buzz." -e "/Fizz/i There's a Fizz." sample.txt
(out)---
(out)There's a Fizz.
(out)Fizz
(out)---
(out)Buzz
(out)There's a Buzz.
(out)---
(out)There's a Fizz.
(out)FizzBuzz
(out)There's a Buzz.
(out)---
(out)There's a Fizz.
(out)FizzBuzzBuzz
(out)There's a Buzz.
変更(Change)
c\
TEXT
GNU拡張記法:
c TEXT
行または範囲を削除し、TEXTを出力する。後続のコマンドがある場合、それらはスキップされ、すぐに次の行の処理へ移る。アドレス指定が範囲指定でない場合は行ごとにTEXTが出力されるが、範囲指定の場合は終了行に達したときに1回だけTEXTが出力される。
sed -e "1,3c Match!" -e "p" sample.txt
(out)Match! <- 1行目から3行目はMatchに変更 pコマンドは実行されない
(out)FizzBuzzBuzz <- pコマンドによる4行目の出力
(out)FizzBuzzBuzz <- デフォルトの4行目の出力
sed "c Match!" sample.txt
(out)Match!
(out)Match!
(out)Match!
(out)Match!
ホールドスペース
sedにはパターンスペースとは別にホールドスペースと呼ばれるバッファがある。ホールドスペースは次の行の処理へ移っても値が保持されるバッファである。ホールドスペースに関係するコマンドを示す。
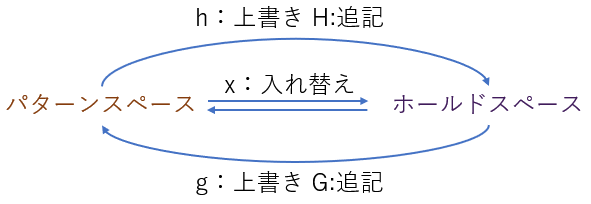
| h | ホールドスペースの内容をパターンスペースの内容で置き換える。 |
| g | パターンスペースの内容をホールドスペースの内容で置き換える。 |
| H | ホールドスペースの末尾に、パターンスペースの内容を新しい行として追記する。 |
| G | パターンスペースの内容に、ホールドスペースの内容を新しい行として追記する。 |
| x | ホールドスペースの内容とパターンスペースの内容を入れ変える。 |
ホールドスペースを使って、入力内容を逆順に出力する例を示す。
sed -n 'x; 1!H; ${x;p}' sample.txt
(out)FizzBuzzBuzz
(out)FizzBuzz
(out)Buzz
(out)Fizz
その他のコマンド
| l length | パターンスペースを「曖昧でない(unambiguous)」書式で出力する。オプションlengthには折り返す文字数を指定する。指定が無いまたは0のときは折り返さない。 曖昧でない書式では、折り返しと行の終わりが明確に区別され、出力不可能な文字はC言語形式でエスケープ出力される。具体的には折り返しの場所に\、行の終わりに$が付けられる。 | FizzBuzzBuzzを出力すると FizzBuzzBuzz$FizzBuzzBuzzを7文字で折り返し出力すると FizzBu\となる。 |
| r filename | ファイルの内容を読み込む。読み込んだ内容はキューへ入れられ、次の行へ移るときに出力される。 ファイルが見つからない場合は何も出力されない。 | ファイルの内容はスクリプトの処理対象とはならず、出力されるのみである。 |
| w filename | パターンスペースの内容をファイルへ書き込む。ファイルがなければ新規作成され、あれば上書きされる。 | |
| N | 次の行をパターンスペースへ読み込む。次の行がない場合、sedは終了する。終了するとき、デフォルトの出力処理は実行される。 | |
| D | パターンスペースに改行が含まれていない場合は、dコマンドと同様に、パターンスペースを削除し次の行の処理へ移る。改行が含まれる場合は、最初の改行までのパターンスペース内のテキストを削除した結果のパターンスペースを次の行とみなして処理を再開する。すなわち、新しい入力行を読み取らない。 |
コマンドラインオプション
| -i[suffix] --in-place[=suffix] | 入力ファイルを実行結果(出力内容)で置き換える。 suffixがある場合、suffixを付けたバックアップファイルを作成する。 |
| -n --quiet --silent | パターンスペースの既定出力を無効にする。 |
| -e script --expression=script | 実行するスクリプトを指定する。複数指定可能。 |
| -f scriptfile --file=scriptfile | 実行するスクリプトが記録されたファイルを指定する。 -eと併用可能。 |
| -l length --line-llength=length | lコマンドの折り返し幅を指定する。 |
| <推奨> -E -r --regexp-extended | 拡張正規表現を使う。互換性の観点から-Eの使用が推奨される。 |
| -s --separate | 複数ファイルの入力を、1つの長いストリームではなく、分かれているものと見なす。 |
| -u --unbuffered | バッファの使用量を減らす。 入力では読み込みを最小限にし、出力ではフラッシュを多くする。 |
| -z --null-data --zero-terminated | 入力を改行ではなくNUL区切りとみなす。 これは find -print0のようなNUL区切りの出力をするコマンドの処理に役立つ。 |
| --posix | GNU拡張を無効にする。 |
| --debug | デバッグモードで実行する。処理の詳細が出力される。 |
| --sandbox | サンドボックスモードで実行する。 e、r、wコマンドを無効にし、これらが含まれている場合は実行されることなく終了する。 |
