Pythonまとめ(2.主なデータ型とコレクション)
基本的な型
はじめに
Pythonで使われる基本的な型を示す。
| 種類 | 型名 |
|---|---|
| 数値(整数) | int |
| 数値(浮動小数) | float |
| 論理 | bool |
| 日時 | datetime |
| 文字列 | str |
複数の要素を保持する型をコレクションという。主なコレクションを示す。
| 種類 | 型名 |
|---|---|
| リスト(配列) | list |
| タプル | tuple |
| 辞書 | dictionary |
| 集合 | set |
数値型
Pythonでは数値を表す型として整数値を表すintと浮動小数点を表すfloatがある。Python3ではintではビット長が定められておらず、メモリの許す限り大きな値を扱える。一方でfloatは64bitの浮動小数点表現である。
a = 124
b = 12.5
type(a)
(out)<class 'int'>
type(b)
(out)<class 'float'>
floatは浮動小数点表現であるため誤差が生じる。試しに0.3-0.2-0.1という計算をしてみると、0にとても近い値(\textrm{-2.7…e-17} \risingdotseq -0.000000000000000027)になる。
0.3-0.2-0.1
(out)-2.7755575615628914e-17
0.3-0.2-0.1 == 0
(out)False
高精度な計算を必要とするときはdecimalパッケージが利用できる。同じ計算をdecimalパッケージで行うと0の結果が得られる。
import decimal as d
d.Decimal('0.3')-d.Decimal('0.2')-d.Decimal('0.1')
(out)Decimal('0.0')
d.Decimal('0.3')-d.Decimal('0.2')-d.Decimal('0.1') == 0
(out)True
浮動小数点の等価比較
decimalパッケージを使用しないで浮動小数点を比較するには、2つの値が十分に近いときに等価であるとみなす。mathパッケージのmath.iscloseメソッドが利用できる。
よく使う数値演算・関数
算術演算子
| 計算 | 演算子 |
|---|---|
| 足し算 | + |
| 引き算 | - |
| 掛け算 | * |
| べき乗 | ** |
| 割り算 | / |
| 割り算の商 | // |
| 割り算の余り(剰余) | % |
数学演算
| 計算 | 関数/演算子 | サンプル | 実行結果 |
|---|---|---|---|
| 絶対値 | abs( x ) | abs( -14 ) | 14 |
| 四捨五入 | round( x, 桁数 ) | round( 12.345, 1 ) | 12.3 |
round( 12.345, -1 ) | 10.0 | ||
| 単純切り捨て | math.trunc( x ) | math.trunc( 15.8 ) | 15 |
math.trunc( -15.8 ) | -15 | ||
| -方向の切り捨て(床関数) | math.floor( x ) | math.floor( 15.8 ) | 15 |
math.floor( -15.8 ) | -16 | ||
| 切り上げ(天井関数) | math.ceil( x ) | math.ceil( 15.8 ) | 16 |
math.ceil( -15.8 ) | -15 | ||
| 最大公約数 | math.gcd( x, y ) | math.gcd( 1134, 3132 ) | 54 |
| 最小公倍数 | math.lcm( x, y ) | math.lcm( 1134, 3132 ) | 65572 |
| 平方根 | math.sqrt( x ) | math.sqrt( 2 ) | 1.41421356.. |
| n乗根 | x ** (1/n) | 27 ** (1/3) | 3 |
三角関数
| 計算 | 演算子 | サンプル | 実行結果 |
|---|---|---|---|
| sin(正弦) | math.sin( rad ) | math.sin( math.radians(30) ) | 0.499... |
| cos(余弦) | math.cos( rad ) | math.cos( math.radians(30) ) | 0.866... |
| tan(正接) | math.tan( rad ) | math.tan( math.radians(30) ) | 0.577... |
角度の単位
角度の単位はラジアンである。度とラジアンを変換する関数として math.degrees()、math.radians()がある。
逆三角関数
逆三角関数はaをつける。たとえばarcsin(逆正弦)ならmath.asin( x )となる。なお、逆正接にはmath.atan( x )とmath.atan2( y, x )の2つがある。atanは与えられた辺の比率となる角度\theta (-\dfrac{\pi}{2} \leqq \theta \leqq \dfrac{\pi}{2})を返す。atan2はXY平面上の点における偏角\thetaを返す。例えばmath.atan2(-1,-1)は-135度に相当するラジアンを返す。
数学定数
| 定数 | 定義 |
|---|---|
| 円周率 | math.pi |
| 自然対数の底 | math.e |
論理型 bool
boolは真(True)、偽(False)を表すオブジェクトで、intのサブクラスである。Trueは1であり、Falseは0である。
True + True
(out)2
bool以外のオブジェクトを論理型に変換する場合、以下のオブジェクトがFalseとして扱われる。
- None
- 数値型において0であるもの(0.0やDecimal(0)などを含む)
- コレクションにおいて空であるもの
- 空文字列("")を含む
この定義から、文字列varが空かあるいはNoneであることを確認したいならif not var:のように書くだけで良いことになる。
比較演算子
比較演算子は2つのオブジェクトを比較し、論理値を返す演算子である。オブジェクトによって小さい、大きいの定義は異なることがある。また異なるオブジェクト同士では比較できない場合がある。
| 比較 | 演算子 | サンプル |
|---|---|---|
| 等しい | == | 10 == 20 |
| 等しくない | != | 10 != 20 |
| より小さい(未満) | < | 10 < 20 |
| より大きい(超) | > | 10 > 20 |
| 以下 | <= | 10 <= 20 |
| 以上 | >= | 10 >= 20 |
| 範囲内 | < ... < =付きも可 | 5 < 10 <= 105 < 10 < 15 == 20 ※3個以上も可 |
| 含む | in | 10 in (10,20,30) |
| 含まない | not in | 10 not in (10,20,30) |
| 同じオブジェクト | is | a is b |
型の比較
オブジェクトの型はtype関数で取得でき、isで型が一致するか判定できる。これは型が完全一致している必要があり、派生型では一致しない。そのため型を比較するときはisinstance関数を使うことのほうが個人的には多い。
# 完全一致
type( obj ) is (class1, class2, ...) # 比較対象のクラスが1つだけであればタプルにしなくて良い
# 継承を含む
isinstance( obj, (class1, class2, ...) ) # 比較対象のクラスが1つだけであればタプルにしなくて良いtype関数とisinstance関数の動作の違いを示すサンプルを示す。
class A():
(con) pass
(con)
class B(A):
(con) pass
(con)
a = A()
b = B()
# type比較
type(a) is A
(out)True
type(b) is A
(out)False
# isinstance比較
isinstance(a, A)
(out)True
isinstance(b, A)
(out)True
isinstanceは派生型でも一致するため、boolやIntEnumがintに一致する点などに注意が必要である。
isinstance(True, int)
(out)True
from enum import IntEnum
class Number(IntEnum):
(con) A = 1
(con)
isinstance(Number.A, int)
(out)True
文字列 str
文字列リテラル(文字列定数)
文字列リテラルは1つまたは3つのクオーテーション('または")で囲まれた文字列の定数のことである。
'文字列'
'''文字列'''
"文字列"
"""文字列"""
三重引用符には改行を含めることができる。改行は\nとして扱われる。'で囲んだ文字列リテラルでは"をそのまま文字として使うことができる。逆に"で囲んだ文字列リテラルでは'をそのまま使うことができる。そうでない場合はエスケープが必要となる。
sampletxt = """
(con)"Sample"
(con)'Text'
(con)"""
print(repr(sampletxt))
(out)'\n"Sample"\n\'Text\'\n'
ソースコードの見やすさのためにインデントすると、インデントもリテラルに含まれてしまう。textwrapモジュールのdedent(de-indentの略)を使うと行頭の空白を削除してくれる。
import textwrap
sampletxt = """
(con) "Sample"
(con) 'Text'
(con) """
print(sampletxt)
(out)
(out) "Sample"
(out) 'Text'
(out)
print(textwrap.dedent(sampletxt))
(out)
(out)"Sample"
(out)'Text'
(out)
特殊文字(エスケープシーケンス)
一般的な文字では表現できないが特別な意味があるもの(たとえばバックスペース)を、文字として表現するために特殊文字を使う。Pythonでは「バックスラッシュ+文字」で表される。Pythonでよく使われる特殊文字は以下の通り。
\n改行\tタブ\\バックスラッシュ- 文字として
\を出力するには\\のように2つ重ねる。
- 文字として
\'\"引用符
ロー文字列
ほとんどのエスケープシーケンス処理が無効となる文字列。文字列の前にrをつける。
print('文字\n列')
(out)文字
(out)列
print(r'文字\n列')
(out)文字\n列
ロー文字列において、最後にバックスラッシュを置くことはできない。その場合はr"test" + "\\"のようにする。
フォーマット文字列(フォーマット済み文字列リテラル、f文字列、f-string)
{}内の式が文字列に展開される。{}内で計算も可能。文字列の前にfかFをつける。Python 3.6から導入された。
a=1; b=5
f"{a}+{b}={a+b}"
(out)'1+5=6'
フォーマット文字列は、最初に評価したときに文字列にフォーマットされる。ループなどで値が更新される場合は、ループの中で評価されるようにしなければならない。
a = 1; b = 0
frm = f"{a}+{b}={a+b}"
for i in range(3):
(con) b = i
(con) print(frm)
(con)
(out)1+0=1
(out)1+0=1
(out)1+0=1
なお導入当初はフォーマット文字列に実装上の制約がいくつかあったが、Python 3.12から解放された。たとえば以下の表記は古いバージョンでは動作しないことがある。
val=100
# {}の中で同じ引用符や\t、\nを使う、f文字列を入れる
print(f"{f"\t{val}"}")
(out) 100
# {}の中で改行
print(f"{
(con) val
(con) }")
(out)100
# コメントをつける
print(f"{
(con) val # コメント
(con) }")
(out)100
=指定子
変数の後にイコールをつけると変数名も出力できる。デバッグ向けの機能であり、イコールをつけたときはデフォルトでreprによって文字列に変換されるようになる。
import datetime
now = datetime.datetime.now()
print(f"{now}")
(out)2024-12-22 00:00:16.267894
print(f"{now = }")
(out)now = datetime.datetime(2024, 12, 22, 0, 0, 16, 267894)
書式指定子
文字列に変換するときの書式を指定できる。書式の指定方法については「フォーマット書式」を参照すること。
import datetime
now = datetime.datetime.now()
print(f"{now = }")
(out)now = datetime.datetime(2024, 12, 22, 0, 0, 44, 17317)
print(f"{now = !s}")
(out)now = 2024-12-22 00:00:44.017317
print(f"{now = :%Y-%m-%d}")
(out)now = 2024-12-22
文字リストとしての文字列
文字列は文字のシーケンスとみなすことができる。つまり、forループで1文字ずつ処理でき、インデックスを使用して指定番目の部分文字列を取り出すこともできる。
a = "test"
for char in a:
(con) print(char)
(con)
(out)t
(out)e
(out)s
(out)t
a = "12345"
a[1]
(out)'2'
a[1:-1]
(out)'234'
ただし、この記法で文字列を書き換えることはできない。strはイミュータブルである。
a = "12345"
a[1] = '0'
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)TypeError: 'str' object does not support item assignment
文字列の結合
+演算子で文字列を結合できる。文字列以外と結合するには明示的に変換が必要である。文字列リテラル同士であれば+無しでも結合される。
"str" + "ing"
(out)'string'
"str" "ing"
(out)'string'
a = "str"; b = "ing";
a + b
(out)'string'
a b
(out) File "<stdin>", line 1
(out) a b
(out) ^
(out)SyntaxError: invalid syntax
CSVのように特定の区切り文字を使って結合するには'区切り文字'.join( 文字列のリスト )が便利である。ただしCSVなら行われるべき処理(たとえばセル内改行のような処理)が必要なら、文字列の結合ではなくCSVパッケージを使用するとよい。
','.join(["2012-03-08", "Hana Senou", "Female"])
(out)'2012-03-08,Hana Senou,Female'
文字列のメソッド
主なメソッドを示す。メソッドの一部にはstart,end引数により、文字列の指定範囲に対して実行できる。このstart,endの指定はスライス記法のstr[start:end]と等しい。
種別判定
| メソッド | 概要 |
|---|---|
| str.isalpha() | 文字列が1文字以上であり、すべての文字がユニコードにおいて「*Letter」として定義されているならTrue。 正確にはユニコードにおいて「Lm(Modifier Letter)」、「Lt(Titlecase Letter)」、「Lu(Uppercase Letter)」、「Ll(Lowercase Letter)」、「Lo(Other Letter)」に分類されるもの。 |
| str.isascii() | 文字列が空または全てASCII文字の場合True。 |
| str.isdecimal() | 文字列が1文字以上であり、すべての文字がユニコードにおいて「Decimal Number」(10進数でつかわれる文字)であるならTrue。 |
| str.isdigit() | 文字列が1文字以上であり、すべての文字がユニコードにおいてNumeric Typeが「Decimal」または「Digit」であるならTrue。 |
| str.isnumeric() | 文字列が1文字以上であり、すべての文字がユニコードにおいてNumeric Typeが「Decimal」、「Digit」、「Numeric」であるならTrue。 |
| str.isprintable() | 文字列が印字可能な文字であるか、空であればTrue。非印字可能文字はユニコードで「Other」または「Separator」と定義されているもののうち、半角空白を除いたもののこと。 |
| str.isspace() | 文字列が1文字以上であり、すべての文字がユニコードにおいてNumeric Typeが「Decimal」、「Digit」、「Numeric」であるならTrue。 |
| str.isidentifier() | 文字列がPythonで定義された有効な識別子であればTrue。 Falseやclassのような予約語、キーワードであるかを確認するにはkeywordモジュールのiskeyword関数を使う。 |
| str.isupper() str.islower() | 文字列に大文字/小文字の区別がある文字を1文字以上含み、かつそれらがすべて大文字(または小文字)であればTrue。 |
# isalpha
"abcde".isalpha()
(out)True
"あいうえお".isalpha()
(out)True
"←".isalpha()
(out)False
# isascii
"abcde".isascii()
(out)True
"abcdeあ".isascii()
(out)False
# isdecimal
"123".isdecimal()
(out)True
"-123".isdecimal()
(out)False
"一二三".isdecimal()
(out)False
"١٢٣".isdecimal()
(out)True
# isdigit
"①⒈❶".isdigit()
(out)True
# isidentifier
"Hello".isidentifier()
(out)True
"!Hello".isidentifier()
(out)False
# capital
"あいう".isupper()
(out)False
"あいうA".isupper()
(out)True
(out)
検索
| メソッド | 概要 |
|---|---|
| "sub" in str | strが文字列subを含むならTrue。※メソッドではないがまとめて記載している。 |
| str.startswith(prefix[, start[, end]]) str.endswith(suffix[, start[, end]]) | 指定の文字列で始まる/終わる場合はTrue。 |
| str.count(sub[, start[, end]]) | 文字列subの出現回数を返す。一度一致した文字は再使用されない。 |
| str.find(sub[, start[, end]]) str.rfind(sub[, start[, end]]) | 文字列subを検索し、位置を返す。見つからない場合は-1。str.findは最初にsubが出現した位置を返し、str.rfindは最後に出現した位置を返す。 |
| str.index(sub[, start[, end]]) str.rindex(sub[, start[, end]]) | findと同じだが、見つからなかった場合にValueErrorが発生する。 |
"cde" in "abcde"
(out)True
"cb" in "abcde"
(out)False
"abcde".endswith("cde")
(out)True
"abcde".startswith("cde")
(out)False
"abcde".startswith("cde",2)
(out)True
"aaaaa".count("a")
(out)5
"aaaaa".count("aa")
(out)2
"aaaaa".count("aaa")
(out)1
"abcabc".find("bc")
(out)1
"abcabc".rfind("bc")
(out)4
"abcabc".find("d")
(out)-1
置換・除去
| メソッド | 概要 |
|---|---|
| str.replace(old, new[, count]) | 部分文字列oldをnewで置き換えた文字列を返す。 countが指定された場合、最初のcount個のみ置換する。 |
| str.strip([chars]) str.rstrip([chars]) str.lstrip([chars]) | 文字列の最初と最後にある指定文字charsを取り除く。rstripは末尾のみ、lstripは最初のみ、stripは前後両方。charsは文字列ではなく、除外する文字のリストとして扱われる。charsの指定がない場合は空白文字(全半スペースや改行、タブなど)が取り除かれる。 |
| str.removeprefix(prefix) str.removesuffix(suffix) | 文字列のプレフィックス、サフィックスを取り除いた文字列を返す。該当の文字を含まない場合はそのままの値が返される。 |
"abcabc".replace("bc", "nd")
(out)'andand'
"abcabc".replace("bc", "nd", 1)
(out)'andabc'
"\n abcde \t".strip()
(out)'abcde'
"\n abcde \t".lstrip()
(out)'abcde \t'
"\n abcde \t".rstrip()
(out)'\n abcde'
"abcdeabcdea".strip("abc")
(out)'deabcde'
"abcde".removeprefix("abc")
(out)'de'
"abcde".removesuffix("abc")
(out)'abcde'
分割・結合
| メソッド | 概要 |
|---|---|
| str.split(sep=None, maxsplit=1) str.rsplit(sep=None, maxsplit=1) | 文字列を区切り文字sepで分割したリストにする。区切り文字が連続した場合、長さが0の文字列があるとみなされる。分割する最大回数はmaxplit回であり、リストの長さは最大でmaxsplit+1になる。 sepが指定されないまたはNoneの場合は、挙動が異なる。区切り文字は空白文字が使われ、連続した空白文字は1つの区切りとみなされる。 |
| str.partition(sep) str.rpartition(sep) | 区切り文字sepで文字列を前後に分割する。結果は(区切り文字の前, 区切り文字, 区切り文字の後)のタプルとなる。 patitionは最初の区切り文字、rpartitionは最後の区切り文字で分割する。 |
| str.splitlines(keepends=False) | 文字列を改行で分割したリストを返す。改行は\nだけでなく\r(復帰)や\v(垂直タブ)なども含まれる。keependsがFalseの場合、分割したリストには改行文字は含まれない。 改行が連続する空行は空文字としてリストに含まれる。ただし「空文字」や「改行で終わる文字列の最後の行」はリストに含まれない。 |
| str.join(iterable) | iterableの文字列を結合する。文字列を区切るセパレータは自身(str側)となる。 |
# split
" 1 2 3 5 ".split(" ")
(out)['', '1', '2', '3', '', '5', '']
# sepを指定しない場合、挙動が異なる
" 1 2 3 5 ".split()
(out)['1', '2', '3', '5']
# partition
"1,2,3,,5,".partition(",")
(out)('1', ',', '2,3,,5,')
"1,2,3,,5,".partition(" ")
(out)('1,2,3,,5,', '', '')
# splitlines
"a\nb\r\vc\f".splitlines()
(out)['a', 'b', '', 'c']
# 空文字だと空のリストになる
"".splitlines()
(out)[]
# 末尾が改行だと最後の空行はリストに含まれない
"a\n".splitlines()
(out)['a']
# join
",".join(["a","b","cde"])
(out)'a,b,cde'
ケース
| メソッド | 概要 |
|---|---|
| str.upper() str.lower() | 文字列を大文字/小文字に統一した文字列を返す。 |
| str.title() | 単語の1文字目だけを大文字、残りを小文字にする。 引用符を含む場合など、正しく動作しないケースが有る。 |
| str.swapcase() | 大文字を小文字に、小文字を大文字にする。 |
パディング
| メソッド | 概要 |
|---|---|
| str.center(width[, fillchar]) str.ljust(width[, fillchar]) str.rjust(width[, fillchar]) | 文字列を幅widthで中央寄せ/左寄せ/右寄せにした文字列を返す。パディング文字にfillcharを使用する。省略時は半角空白。 |
| str.zfill(width) | 文字列を幅widthで右寄せにし、0でパディングした文字列を返す。+-記号で始まる場合は1文字目が記号となるようにパディングされる。(zerofill) |
"1000".center(12,"-")
(out)'----1000----'
"1000".rjust(12,"-")
(out)'--------1000'
"1000".ljust(12,"-")
(out)'1000--------'
"123".zfill(5)
(out)'00123'
"-123".zfill(5)
(out)'-0123'
"+あ".zfill(5)
(out)'+000あ'
日時型 dateとdatetime
Pythonの日時に関係するものとして、date、datetime、time、timezoneがある。主な特徴を示す。
| クラス | 特徴 | ライブラリ | 用途の例 |
|---|---|---|---|
| date | 日付を表す | datetime | 現在の日付を取得 |
| datetime | 日付と時刻を表す | datetime | 現在の日付と時刻を取得 |
| timezone | タイムゾーンを表す | datetime | タイムゾーンの操作 |
| time | 時間を表す | time | UNIX時間の取得、sleep |
タイムゾーン
Python2ではタイムゾーンを扱うためにpytzライブラリを使用していたが、Python3からdatetimeが標準でタイムゾーンを取り扱うことができる。datetime.nowとdatetime.utcnowという2つの現在日時を取得するメソッドが用意されている。
from datetime import datetime,date,timezone
# ローカル時刻で現在日時を取得
datetime.now()
(out)datetime.datetime(2023, 7, 17, 22, 23, 49, 145537)
date.today()
(out)datetime.date(2023, 7, 17)
# UTCで現在日時を取得
datetime.utcnow()
(out)datetime.datetime(2023, 7, 17, 13, 26, 31, 339851)
datetime.utcnow().date()
(out)datetime.date(2023, 7, 17)
datetime.nowは引数でタイムゾーンを明示的に指定して現時刻を取得できる。この場合、作成したdatetimeにもタイムゾーン情報が入っている。
from datetime import datetime,timezone,timedelta
# タイムゾーンを明示的に指定して現在日時を取得
jst = timezone(timedelta(hours=+9), 'JST')
datetime.now(jst)
(out)datetime.datetime(2024, 12, 22, 0, 27, 41, 896804, tzinfo=datetime.timezone(datetime.timedelta(seconds=32400), 'JST'))
datetime.now(jst).date()
(out)datetime.date(2024, 12, 22)
指定時刻のオブジェクトを作成する
from datetime import datetime,date
datetime(2022,5,12,15,30,24,34567)
(out)datetime.datetime(2022, 5, 12, 15, 30, 24, 34567)
date(2022,5,13)
(out)datetime.date(2022, 5, 13)
年月日時分の一部だけを取り出す
from datetime import datetime
dt = datetime(2022,5,12,15,30,24,34567)
dt.year
(out)2022
dt.month
(out)5
dt.day
(out)12
dt.hour
(out)15
dt.minute
(out)30
dt.second
(out)24
dt.microsecond
(out)34567
dt.weekday() # 月曜始まりで月曜が0
(out)3
dt.isoweekday() # 月曜始まりで月曜が1
(out)4
時間を操作する
date、datetimeはイミュータブルであり更新できない。replaceメソッドで一部を置き換えた別のオブジェクトを取得できる。
dt1 = datetime(2023,7,17,20,00)
str(dt1)
(out)'2023-07-17 20:00:00'
dt2 = dt1.replace(year=2500,month=8,day=5,hour=0,minute=0)
str(dt2)
(out)'2500-08-05 00:00:00'
時間の差
dateやdatetimeの差を求めるとtimedeltaオブジェクトが得られる。
dt1 = datetime(2023,7,17,20,00)
dt2 = datetime(2023,7,17,21,30)
dt2-dt1
(out)datetime.timedelta(seconds=5400)
dt1-dt2
(out)datetime.timedelta(days=-1, seconds=81000)
逆にtimedeltaを使って時間を進めたり戻したりできる。
dt1 = datetime(2023,7,17,20,00)
dt1 + timedelta(days=1) # dayではなくdaysであることに注意
(out)datetime.datetime(2023, 7, 18, 20, 0)
relativedelta
timedeltaでは週数や日数を指定してオブジェクトを作成できるが、月や年単位では作成できない。timedeltaのコンストラクタは以下のように定義されている。
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)つまり、timedeltaは1年後のような指定ができない。代わりに日数で365日後と指定することはできるが、この方法では閏年が考慮されない。
import datetime
dt = datetime.datetime.now()
dt
(out)datetime.datetime(2023, 7, 22, 17, 57, 57, 462458) # 今日は7月22日
dt + datetime.timedelta(days=365)
(out)datetime.datetime(2024, 7, 21, 17, 57, 57, 462458) # 365日後は7月21日。閏年のため1日ずれている。
そのような場合はdateutilのrelativedeltaを使うと翌月や翌年の指定ができる。dateutilは追加インストール(pip install python-dateutil)が必要である。
import datetime
from dateutil.relativedelta import relativedelta # relativedeltaをインポート
dt = datetime.datetime.now()
dt
(out)datetime.datetime(2023, 7, 22, 17, 57, 57, 462458) # 今日は7月22日
dt + relativedelta(years=+1)
(out)datetime.datetime(2024, 7, 22, 17, 57, 57, 462458) # 1年後は7月22日。閏年が考慮されている。
日時と文字列の変換
日時と文字列を変換するには、日時→文字列はstrftimeメソッド、文字列→日時はstrptimeメソッドを使う。
日時を文字列に変換する例
# ISOフォーマット
date1 = datetime.now(jst).date()
datetime1 = datetime.now(jst)
date1.isoformat()
(out)'2023-07-17'
datetime1.isoformat()
(out)'2023-07-17T22:52:19.535502+09:00'
date1.strftime('%Y-%m-%d %H-%M-%S.%f')
(out)'2023-07-17 00-00-00.000000'
datetime1.strftime('%Y-%m-%d %H-%M-%S.%f')
(out)'2023-07-17 22-52-19.535502'
datetime1.strftime('%Y-%m-%d(%a) %H-%M-%S.%f %Z')
(out)'2023-07-17(Mon) 22-52-19.535502 JST'
strftimeで使用できるものの一覧はstrftime() and strptime() Format Codesにある。
文字列をdatetimeオブジェクトに変換する例
datetime.strptime("2023-07-17", "%Y-%m-%d") # 任意のフォーマット
(out)datetime.datetime(2023, 7, 17, 0, 0)
datetime.fromisoformat("2022-05-12T15:30:24") # ISOフォーマット
(out)datetime.datetime(2022, 5, 12, 15, 30, 24)
複数要素を保持できる型(コレクション)
Pythonでは複数要素を保持できる型をコレクションとよぶ。主なコレクションに配列(list)、タプル(tuple)、辞書(dictionary)、集合(set)がある。主な特徴は以下の通りである。
| 型 | 表記方法 | コレクションの要素へのアクセス方法 | 特徴 |
|---|---|---|---|
| 配列 | 角括弧[a, b, c] | ゼロベースのインデックスを使用list[0] | 最も標準的な順序付きコレクション。 |
| タプル | 丸括弧( a, b, c ) | ゼロベースのインデックスを使用tuple[0] | イミュータブルな順序付きコレクション。 |
| 辞書 | 波括弧とコロン{"key1":value1, "key2":value2} | キーを使用dict["key1"] (キー) | キーバリュー型の順序なしコレクション。 |
| 集合 | 波括弧{a, b, c} | 順番やキーを持たないため不可 | 重複しない集合演算可能なコレクション。 |
コレクションの共通な特徴は以下の通りである。
- len()で要素数が取得できる
- in演算子でコレクションの中にある要素が含まれるかどうかを判定できる
シーケンス
要素に順序があり、整数の順序番号(インデックス)で要素にアクセスできる特徴を持つコレクションをシーケンスという。配列、タプルはどちらもシーケンスである。
シーケンスのインデックスは0始まりである。また末尾から数えた順序番号を負数で指定できる。要素数10のシーケンスでインデックスの例を示す。
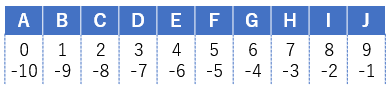
sequence = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
sequence[3]
(out)'D'
sequence[-1] # インデックスを-1にすると常に最後の要素を返す(要素がない時を除く)
(out)'J'
存在しないインデックスを指定するとインデックスエラーが発生する。
sequence[20]
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)IndexError: list index out of range
スライス
シーケンスは整数インデックスにより指定番目の要素へアクセスできるが、スライスを使うと指定された範囲にある要素を取り出せる。スライスは以下のようにコロンで範囲を指定する。
sequence[ 開始位置(start) : 終了条件(stop) ]スライスで取り出されるのは取り出し開始位置から終了条件に達するまでとなり、終了条件に指定した要素は取り出されない。たとえば[3:5]と指定した場合、得られる要素はインデックスが3と4のものである。
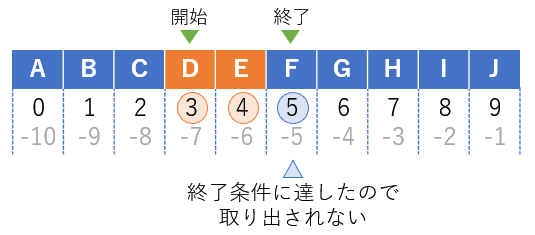
sequence[3:5]
(out)['D', 'E']
インデックスはマイナスでもよいため、開始位置を3の代わりに-7、終了位置を5の代わりに-5としても問題ない。そのため4通りのスライス指定ができる。
sequence = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
sequence[3:5]
(out)['D', 'E']
sequence[3:-5]
(out)['D', 'E']
sequence[-7:-5]
(out)['D', 'E']
sequence[-7:5]
(out)['D', 'E']
スライスではインデックスを省略できる。開始位置を省略した場合は0、終了条件を省略した場合は要素数が指定されたと見なされる。
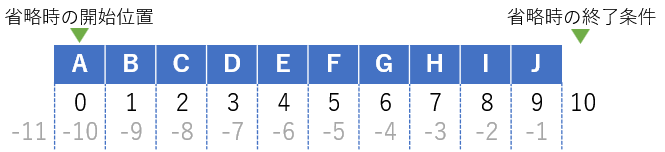
これを活用すると先頭n個(あるいは末尾n個)を取り出すことが簡単にできる。
sequence[:3]
(out)['A', 'B', 'C']
sequence[-3:]
(out)['H', 'I', 'J']
なお、スライスでは範囲外のインデックスを指定してもエラーにならず、取り出せるものだけ取り出される。取り出せるものがない場合は空のシーケンスが得られる。
sequence[5:20]
(out)['F', 'G', 'H', 'I', 'J']
sequence[10:20]
(out)[]
拡張スライス
シーケンスの一部では拡張されたスライス(拡張スライス)も使用できる。拡張スライスでは取り出し間隔が指定できる。本記事中では拡張スライスでは無いスライスのことを便宜上「標準のスライス」と呼ぶことがある。
sequence[ 取り出し開始位置(start) : 取り出し終了条件(stop) : 取り出し間隔(step) ]拡張スライスは取り出し開始位置から間隔ごとに、終了条件に達するまで取り出していく。例えば、[0:5:2]とすると、下図のようにインデックスが0、2、4の要素が取り出される。
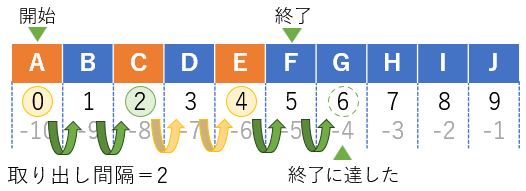
sequence[0:5:2]
(out)['A', 'C', 'E']
取り出し間隔をマイナスにすると逆順に取り出す。このとき取り出し位置も開始位置>終了位置と大小関係が逆転する。たとえばインデックスが2から4までを逆順で取り出す場合では、取り出し開始位置は4、取り出し終了条件を1とすると実現できる。
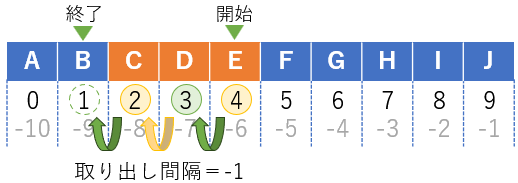
sequence[4:1:-1]
(out)['E', 'D', 'C']
開始位置や終了位置を省略した場合も正のときと位置関係が逆になる。(正確には開始位置が-1、終了位置は-(要素数+1)の位置になる)

逆順で先頭3個、末尾3個を取り出すときは以下のようになる。※インデックスの考え方を残すために、あえて計算を省略していない。
sequence[(3-1)::-1]
(out)['C', 'B', 'A']
sequence[:-(3+1):-1]
(out)['J', 'I', 'H']
しかし、直感的ではないので普通に取り出してから逆順に並び替えた方が良い。
list(reversed(sequence[:3]))
(out)['C', 'B', 'A']
スライスへの代入
スライス記法は値を取り出すだけでなく、代入先としても使用できる。代入によりシーケンスの長さが拡張・縮小されることがある。
標準のスライスに代入すると、その部分が置換される結果になる。
a = [1, 2, 3, 4, 5]
a[2:] = ["a", "b"]
a
(out)[1, 2, 'a', 'b']
a = [1, 2, 3, 4, 5]
a[:2] = ["a","b","c","d","e"]
a
(out)['a', 'b', 'c', 'd', 'e', 3, 4, 5]
a = [1, 2, 3, 4, 5]
a[2:4] = ["a","b","c","d","e"]
a
(out)[1, 2, 'a', 'b', 'c', 'd', 'e', 5]
長さが0になる標準のスライスでは、そこに挿入される。
a = [ 1, 2, 3, 4, 5 ]
a[1:1]
(out)[]
a[1:1] = [ "a","b","c","d","e" ]
a
(out)[1, 'a', 'b', 'c', 'd', 'e', 2, 3, 4, 5]
# レンジ外のスライス指定での挿入例
a = [ 1, 2, 3, 4, 5 ]
a[100:200] # レンジ外のスライス指定も長さが0になるので
(out)[]
a[100:200] = ['a', 'b', 'c'] # こうすると末尾への挿入になる
a
(out)[1, 2, 3, 4, 5, 'a', 'b', 'c']
拡張スライスへの代入
拡張スライスを代入先として指定すると、各要素を置き換える動作となる。
a = [ 1, 2, 3, 4, 5 ]
a[::2]
(out)[1, 3, 5] # 要素数が3の拡張スライス
a[::2] = ['a', 'b', 'c'] # 要素数が同じ3のリストを代入
a
(out)['a', 2, 'b', 4, 'c']
拡張スライスの要素数と代入するコレクションの要素数が一致しないとエラーになる。
a = [ 1, 2, 3, 4, 5 ]
a[::2]
(out)[1, 3, 5] # 要素数が3の拡張スライス
a[::2] = ['a', 'b', 'c', 'd', 'e'] # 要素数5を代入
(out)ValueError: attempt to assign sequence of size 5 to extended slice of size 3
(out)# ValueError:サイズが3の拡張スライスにサイズが5のシーケンスを割り当てようとした
仮に要素数が0であっても拡張スライスであれば挿入では無くエラーになる。
a = [ 1, 2, 3, 4, 5 ]
a[2:2:-1]
(out)[]
a[2:2:-1] = ['a', 'b', 'c', 'd', 'e']
(out)ValueError: attempt to assign sequence of size 5 to extended slice of size 0
ただし、拡張スライス記法であっても取り出し間隔が1であれば標準的なスライスと同じように挿入や置換が行われる。
a = [ 1, 2, 3, 4, 5 ]
a[2:2:-1]
(out)[]
a[2:2:-1] = ['a', 'b', 'c', 'd', 'e']
(out)ValueError: attempt to assign sequence of size 5 to extended slice of size 0
a[2:2:1]
(out)[]
a[2:2:1] = ['a', 'b', 'c', 'd', 'e']
a
(out)[1, 2, 'a', 'b', 'c', 'd', 'e', 3, 4, 5]
マッピング
要素に順序がなく、一意のキーで対応する要素にアクセスできるコレクションをマッピングという。キーバリュー型、キー付きコレクションなどとも呼ばれることがある。
辞書はマッピングであり、キーが商品名、バリューが在庫数である辞書stockは以下のように作成できる。要素にアクセスするときは [キー名] を付ける。
stock = {"Apple":100, "Bread":200}
stock["Apple"]
(out)100
キーは文字列で無くてもよい。ただ辞書はハッシュ値を使用してキーを管理しているため、ハッシュ可能でなければならない。例としてハッシュ不可能であるリストをキーにした辞書を作成してみた。他にハッシュ不可能なものとしては辞書やセットなどがある。
unhashable_list = [1, 2, 3, 4]
dict1 = { unhashable_list:100 }
(out)TypeError: unhashable type: 'list'
独自に作成したクラスは基本的にはハッシュ可能となっているが、使い方によっては予期せぬ動作をするかもしれない。
キーの存在確認
存在しないキーにアクセスするとKeyErrorとなる。
dict = {} # dictは空の辞書
dict["key"] # 存在しないkeyにアクセス
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)KeyError: 'key'
ディクショナリにとあるキーが存在するかはin演算子でテストできる。
"key" in dict
(out)False
複数のキーがあるかを一括で確認したいならdict.keysメソッドを使用できる。dict.keys()は辞書が持つキー一覧を取得するメソッドであるが、このキー一覧はSetのようなオブジェクト(set-like object)になっており、不等号で包含関係を比較できる。つまり>、>=、<、<=は数学の集合論でいう⊃、⊇、⊂、⊆にそれぞれ相当する。
import collections.abc
dicta = { "a":1, "b":2, "c":3 }
isinstance(dicta.keys(), collections.abc.Set)
(out)True
dicta.keys() >= {"a","b"}
(out)True
dicta.keys() >= {"a","b","d"}
(out)False
なお、辞書をsetに変換しても同じ結果が得られる。
dicta = { "a":1, "b":2, "c":3 }
set(dicta)
(out){'c', 'a', 'b'}
存在しないキーへのアクセス
もし存在しないキーでもエラーにしたくないならget()を使う。getメソッドでは第2引数でキーが存在しなかった場合の値を指定でき、デフォルトではNoneになる。
dicta = {}
dicta.get("key")
dicta.get("key", 0)
(out)0
defaultdict
ケースによってはdefaultdictのほうが使いやすいことがある。defaultdictは存在しないキーを参照するときにデフォルト値を返すため、つねにgetでアクセスしているかのように使うことができる。例として空のリストを初期値にもつdefaultdictは以下のように実装できる。
from collections import defaultdict # defaultdictは標準型ではないためインポート必要
defdict = defaultdict(lambda:0) # 引数で初期化する関数を指定、常に0を返すlambda関数を渡している。
defdict["key"] # defaultdictで存在しないkeyにアクセス
(out)0
使用例
重複ありリストで要素の出現回数をカウントするプログラムを考えてみる。普通の辞書を使うと以下のように書けるだろう。
target = [0,3,5,6,3,2,4,7,1,5]
counter = dict()
for no in target:
(con) counter[no] = counter.get(no,0) + 1
(con)
counter
(out){0: 1, 3: 2, 5: 2, 6: 1, 2: 1, 4: 1, 7: 1, 1: 1}
これはcounter辞書が要素の出現回数を記録する変数であり、forループの中で辞書の値を1ずつ増やしている。初めて出現した要素だと辞書にキーが無いためgetを使ってこれまでの出現回数を取得しているというわけである。続いてdefaultdictを使うとgetを使わなくてよいので、累算代入(加算代入)を使用して以下のように書くことができる。
from collections import defaultdict
target = [0,3,5,6,3,2,4,7,1,5]
counter = defaultdict(lambda:0)
for no in target:
(con) counter[no] += 1
(con)
counter
(out)defaultdict(<function <lambda> at 0x000001D7AA68C360>, {0: 1, 3: 2, 5: 2, 6: 1, 2: 1, 4: 1, 7: 1, 1: 1})
値の取り出し
dictはkeys、values、itemsメソッドで、それぞれキーの一覧、バリューの一覧、キーとバリューの一覧を取り出せる。
stock = {"Apple":100, "Bread":200}
stock.keys()
(out)dict_keys(['Apple', 'Bread'])
stock.values()
(out)dict_values([100, 200])
stock.items()
(out)dict_items([('Apple', 100), ('Bread', 200)])
| dict.keys() | キーのリストを取得 |
| dict.values() | 値のリストを取得 |
| dict.items() | キーと値の組み合わせ(タプル)のリストを取得 |
セット
セット(集合)は、順序がなく、要素が重複しないコレクションである。集合演算を行いたいときや重複除外したいときに使うことができる。
set = { "Apple", "Bread", "Apple", "Apple" }
set
(out){'Apple', 'Bread'}
この例を見ると重複している要素"Apple"が1つにまとめられていることが分かる。
集合演算
セットでは和集合や積集合を求められる。A = {0,1,2,3,4,5,6,7,8,9,10}、B = {2,3,5,7,11,13,17,19}のとき、以下のような結果が得られる。
| 和集合(AかBに含まれる) | A | B | {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 17, 19} |
| 差集合(Aにだけある) | A - B | {0, 1, 4, 6, 8, 9, 10} |
| 積集合(AとBの両方にある) | A & B | {2, 3, 5, 7} |
| 対象差集合(AかBのどちらか一方だけにある) | A ^ B | {0, 1, 4, 6, 8, 9, 10, 11, 13, 17, 19} |
コレクションの比較
大小判定(>、>=、<、<=)
シーケンス
シーケンス同士の大小比較は、最初の要素から要素ごとに順番に比較される。
list1 = [ 'h', 'e', 'l', 'l', 'o' ]
list2 = [ 'h', 'e', 'm', 'l', 'o' ]
list1 < list2
(out)True
この例ではlist1[0] == list2[0], list1[1] == list2[1], list1[2] < list2[2]と順に比較していき、結果はlist1 < list2となる。
要素数の異なるシーケンスの比較では、まず要素ごとの比較が行われ、どちらかの終端に達した時点で違いがない場合は、要素数が少ない方が小さいとされる。
list1 = [10, 20, 30]
list2 = [10, 20, 20, 40]
list1 < list2
(out)False # 3番目の要素がlist2の方が小さい
list1 = [10, 20, 30]
list2 = [10, 20, 30, 40]
list1 < list2
(out)True # 3番目の要素までは同じだが、list1の方が要素数が少ない
辞書
辞書は大小比較をサポートしない。
集合
集合は大小比較演算子は包含判定として動作する。
set1 = {1, 2, 3, 4, 5}
set2 = {5, 4, 3, 2, 1}
set3 = {1, 5, 3}
set4 = {1, 2, 8}
set1 >= set2
(out)True
set1 > set3
(out)True
set1 > set4
(out)False
一致判定
==演算子でコレクションの比較ができる。シーケンス(順序付きコレクション)である場合、順序も一致している必要がある。
# リストでの比較
list1 = [10,20,30]
list2 = [10,20,30]
list3 = [30,20,10] # 中身は同じだが順序が異なる
list1 == list2
(out)True
list1 == list3
(out)False
# 辞書型は順序を持たないためキーバリューの組み合わせがすべて一致していれば良い。
dict1 = { "key1":10, "key2":20 }
dict2 = { "key2":20, "key1":10 } # 見た目上の順序は異なる
dict1 == dict2
(out)True
もしシーケンスで順序不問で一致判定をしたいなら、setを使うことを考えてみても良い。setは集合オブジェクトであり、要素の順序と重複した要素が無視される。
list1 = [10,20,30]
list2 = [30,20,10]
set1 = set(list1)
set2 = set(list2)
set1 == set2
(out)True
ただしsetは重複除外もしているため同じ値が異なる回数出現するシーケンスでも一致する。これが好ましくない動作ならDeepDiffライブラリなどを使用するか、シーケンスをソートしてから比較するのもよいだろう。
list3 = [10,20,30,30,20,10]
set3 = set(list3)
set3
(out){10, 20, 30}
set1 == set3
(out)True
list1 = [10, 20, 30]
list2 = [30, 20, 10]
list1 == list2
(out)False
sorted(list1) == sorted(list2)
(out)True
イテレータ
コレクションの中にはイテレータと呼ばれるものを使って要素に順次アクセスできるものがある。そのようなコレクションはiterableであるという。イテレータを使う例を示す。
collection = [1,2,3]
iterator = iter(collection)
next(iterator)
(out)1
next(iterator)
(out)2
next(iterator)
(out)3
next(iterator)
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)StopIteration
組み込み関数iterとnextを使用している。iterableなコレクションを引数としてiterを実行するとイテレータが得られる。そのイテレータを引数としてnextを実行すると1つずつ要素を取り出すことが出来るという仕組みである。最後の要素に達するとStopIteration例外が発生する。
iterableなコレクションはfor … inをつかって要素を順に処理できる。
for item in iterable_collection:
print(item)配列、タプル、辞書、セットはいずれもiterableである。例としてタプルで要素を処理する例を示す。
item_tuple = ("Apple", "Bread")
for item in item_tuple:
(con) print(item)
(con)
(out)Apple
(out)Bread
配列とタプルでは、コレクションの要素が順にitemに入り処理されるが、辞書のようなマッピングではキーの値が順にitemに入ることになる。もし辞書でバリューだけを取り出して順次処理をしたい場合は、辞書のvaluesメソッドでバリューのコレクションを取得すれば良い。
stock_dict
(out){'Apple': 100, 'Bread': 200}
for item in stock_dict:
(con) print(f"{item=}")
(con) print(f"{stock_dict[item]=}")
(con)
(out)item='Apple'
(out)stock_dict[item]=100
(out)item='Bread'
(out)stock_dict[item]=200
for stock in stock_dict.values():
(con) print(stock)
(con)
(out)100
(out)200
ここでイテレータおよびiterableの動作についてもう少し補足するために、組み込み関数iterとnextを使わずにイテレータを使うコードを紹介する。
collection = [1,2,3]
iterator = collection.__iter__()
iterator.__next__()
(out)1
iterator.__next__()
(out)2
iterator.__next__()
(out)3
iterator.__next__()
(out)StopIteration
イテラブルなコレクションは__iter__メソッドを実装している。このメソッドはコレクションの要素に順次アクセスできるイテレータを返す。このイテレータは__next__メソッドを実装している。このメソッドを呼び出すと次の要素を返すか、終端に達したことを示すStopIteration例外を送出する。for ... inの構文はイテレータというものを深く意識すること無く要素に順次アクセスする処理を実現するものである。
コレクションの長さ
コレクションの要素数は組み込み関数lenで得られる。
len(dict1)
(out)3
enumerate
繰り返しのときに要素だけでなく順序番号も取得できるenumerate関数が用意されている。enumerateはインデックスと値の組み合わせをタプルで返す。
for (index,value) in enumerate(collection):
print(f"collection[{index}]={value}")
タプルの()は省略できるため、実際には以下のような表記がされることが多い。
for index,value in enumerate(collection):
辞書型に対してenumerateを使用した場合、キーとキーの順序番号が得られる。なお、辞書型はPython 3.7からキーの順序が保証されるようになった。
dicta = {"key1":100, "key2":200}
dict_a = {"key1":100, "key2":200}
for i,v in enumerate(dict_a):
(con) print(f"{i=},{v=}")
(con)
(out)i=0,v='key1'
(out)i=1,v='key2'
enumerateは第二引数で開始番号を指定できる。Pythonではシーケンスは0からインデックスが始まる(ゼロベースのインデックス)が、人が見る場合は先頭が1番のほうが自然である。そのような場合に1から開始するように指定できる。
list_a = "hello"
for i,v in enumerate(list_a, 1):
(con) print( f"{i=}, {v=}" )
(out)i=1, v='h'
(out)i=2, v='e'
(out)i=3, v='l'
(out)i=4, v='l'
(out)i=5, v='o'
ただし開始番号を指定した場合、本当のインデックスとenumerateが返す順序番号がずれるため、その値をインデックスとして使わないように注意すること。
for i,v in enumerate(list_a, 1):
(con) print( f"{i=}, {v=}, {list_a[i]=}" )
(out)i=1, v='h', list[i]='e'
(out)i=2, v='e', list[i]='l'
(out)i=3, v='l', list[i]='l'
(out)i=4, v='l', list[i]='o'
(out)Traceback (most recent call last):
(out) File "<stdin>", line 2, in <module>;
(out)IndexError: string index out of range
なお、正確にはenumerate関数はenumerateオブジェクトを返す。このenumerateオブジェクトは後述するgenerator iteratorに等しい。番号と値のタプルのリストを取得したいならlist関数と組み合わせる。
enumerate(["a","b"],0)
(out)<enumerate object at 0x0000020A85D79380>
list(enumerate(["a","b"],0))
(out)[(0, 'a'), (1, 'b')]
要素の追加と削除
| 型 | 要素の追加 | 要素を指定して削除 | 指定位置の要素の削除(取り出し) | すべて削除 |
|---|---|---|---|---|
| list | list1.append( newvalue ) | list1.remove( newvalue )*1*2 | list1.pop( index )*3*4*5 | list1.clear() |
| tuple | 不可(イミュータブル) | 不可(イミュータブル) | 不可(イミュータブル) | 不可(イミュータブル) |
| dict | dict1.[ newkey ] = newvalue*6 | リスト内包表記を使用 | dict1.pop( key )*3*4*5 | dict1.clear() |
*1 存在しない値を与えるとValueErrorになる
*2 複数に一致する場合は、最初に一致したものだけが削除される
*3 popは、取り出すメソッドであり、取り出した要素を返す
*4 存在しないインデックスを与えるとIndexErrorになる
*5 負数の値を指定して、末尾からの位置も指定できる。-1が最後尾である。
*6 キーが既に存在される場合は上書きされる。setdefaultメソッドを使うと、キーが存在する場合は上書きしない処理ができる。dict1.setdefault("key", value)
dictにはpopitem()もあり、LIFOで要素を取り出すこともできる。(Python 3.7以降)
なお追加したい要素がコレクションである場合、コレクションが1つの要素として追加されることに注意すること。コレクションを連結させたいなら下表の方法を使う。
>>> list1 = [1,2,3]; list2 = [4,5,6]
>>> list1.append(list2)
>>> list1
[1, 2, 3, [4, 5, 6]]
>>> list1[3]
[4, 5, 6]| 型 | 既存のコレクションに追加 | 別のコレクションとして作成 |
|---|---|---|
| list | list1.extend(list2) | list3 = list1 + list2 |
| tuple | 不可(イミュータブル) | tuple3 = tuple1 + tuple2 |
| dict | dict1.update(dict2) | dict3 = dict1 | dict2 |
リストを連結する場合、以下のようになる。
list1 = [1,2,3]; list2 = [4,5,6]
list1.extend(list2)
list1
(out)[1, 2, 3, 4, 5, 6]
なお辞書の連結においては重複したキーの値がある場合は上書きされる。そのため正確には連結ではなく更新(メソッド名もupdate)であり、dict1.update(dict2)とdict2.update(dict1)では異なる値になる可能性がある。
dict1 = {1:10,2:20}
dict2 = {1:100,2:200}
print( dict1 | dict2 )
(out){1: 100, 2: 200}
print( dict2 | dict1 )
(out){1: 10, 2: 20}
内包表記(List Comprehensions)
内包表記はリストやディクショナリをfor構文を使用して作成する表記法である。元となるiterableなコレクションがあり、その各要素に対して何らかの処理を行った結果のリストやディクショナリを作成できる。ただしタプルは内包表記では生成できない。タプルのこの表記は別の用途(ジェネレータ式)で定義されている。
# リスト
[ expression for variable_name in itarable ]
# ディクショナリ
{ key_expression:value_expression for variable_name in itarable }
# セット
{ expression for variable_name in itarable }
1~10までの数値のコレクションをもとに、キーが数値、バリューがキーの2乗値となる辞書を作成する例を示す。
datarange = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
{ x:x**2 for x in datarange }
(out){1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}
フィルター
内包表記ではifを使って条件を満たしたイテラブルの要素だけを使用できる。
[ rule_expression for variable_name in itarable if condition_for_iterable ]
1~20の整数の中で3の倍数のリストは、以下の表記で作成できる。
datarange = list(range(1,21))
datarange
(out)[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
[ x for x in datarange if x%3==0 ]
(out)[3, 6, 9, 12, 15, 18]
複数コレクションの内包表記
1つの内包表記にfor...inやifを2個以上書くことができる。以下の2つはどちらもエラーなく実行可能なPythonコードである。
[ x**2 for x in (1,2,3,4,5,6,7,8,9,10) if x > 5 if x%2==0 ]
(out)[36, 64, 100]
[ (x,y,z) for x in (1,2) for y in (1,2) for z in (1,2) if not (x == y and y == z) ]
(out)[(1, 1, 2), (1, 2, 1), (1, 2, 2), (2, 1, 1), (2, 1, 2), (2, 2, 1)]
1つめのリスト内包表記なら、以下のように展開されると考えればよい。
array = []
for x in (1,2,3,4,5,6,7,8,9,10):
(con) if x > 5:
(con) if x%2 == 0:
(con) array.append(x**2)
(con)
array
(out)[36, 64, 100]
forを複数個書く場合は順序に意味があることに注意する。以下にforの順序を入れ替えた場合に現れる際を例示する。
[ (x,y) for x in (1,2) for y in (3,4) ]
(out)[(1, 3), (1, 4), (2, 3), (2, 4)]
[ (x,y) for y in (3,4) for x in (1,2) ]
(out)[(1, 3), (2, 3), (1, 4), (2, 4)]
リストに含まれる値の順序が異なっていることがわかる。これはforループにどう展開されるか考えればわかる。
for x in (1,2):
(con) for y in (3,4):
(con) print(x, y)
(con)
(out)1 3
(out)1 4
(out)2 3
(out)2 4
for y in (3,4):
(con) for x in (1,2):
(con) print(x, y)
(con)
(out)1 3
(out)2 3
(out)1 4
(out)2 4
コレクション向けの便利な関数
コレクションで使える便利な関数を紹介する。なお、関数によってiterableやシーケンスなどコレクションが限定されていることに注意すること。
| sum | イテラブルの要素の合計値を求める。 |
| min | イテラブルの要素の中の最小のものを得る。 |
| max | イテラブルの要素の中で最大のものを得る。 |
| filter | イテラブルの要素の中で条件を満たす要素だけを取り出す。 |
| map | イテラブルの全要素に処理を適用したものを得る。 |
| reversed | シーケンスの要素を逆順に取り出すイテレータを得る。 |
| sorted | イテラブルの要素を整列させたものを得る。 |
| zip | 複数のイテラブルから一つずつ要素を取り出す。 |
| all | イテラブルの要素が全てTrueか調べる。 |
| any | イテラブルの要素にTrueが1つでもあるか調べる。 |
sum
イテラブルなコレクションの合計値を返す。
sum(iterable)
sum(iterable, /, start=0) # startは開始時の値。startとコレクションの値の合計値となる。
startの利用例を示す。コレクションの合計値は60であり、startの値がそれに加算される形となる。
datas = [10, 20, 30]
sum(datas)
(out)60
sum(datas, 100)
(out)160
min
イテラブルなコレクションあるいは引数のリストから最小のものを返す。keyで大小判定に使用する値を指定できる。keyの使用例は次のmaxでまとめて記載する。
min(iterable, key=None) # iterableは空であってはいけない
min(iterable, default, key=None) # こちらはiterableが空でもOK。defaultはiterableが空だったときの値
min(arg1, arg2, *args, key=None) # これはiterableではなく引数で指定する
max
イテラブルなコレクションあるいは引数のリストから最大のものを返す。keyで大小判定に使用する値を指定できる。
max(iterable, key=None) # iterableは空であってはいけない
max(iterable, default, key=None) # こちらはiterableが空でもOK。defaultはiterableが空だったときの値
max(arg1, arg2, *args, key=None) # これはiterableではなく引数で指定する
keyの使用例を示す。keyで指定した関数が返した値に基づいて大小判定が行われている。
datas = [ (10,20), (10,25), (40,10), (30,30) ]
min(datas)
(out)(10, 20)
min(datas, key=lambda x:x[1])
(out)(40, 10)
max(datas, key=lambda x:x[0]+x[1])
(out)(30, 30)
filter
イテラブルなコレクションに対して条件を満たす要素だけを取り出すfilter関数が用意されている。
filter( function, iterable )
filter関数はfunctionが真となる要素だけを取り出す。奇数だけを取り出すフィルターは、ラムダ式を用いて以下のように書ける。filter関数はiterableであるfilterオブジェクトを返す。filterオブジェクトはiterableであり、リストとして使うためにはlist関数を使う。
list1 = [ 1, 6, 3, 10, 5, 9]
filter(lambda x:x%2, list1)
(out)<filter object at 0x000002AE3E2B6080>
list(filter(lambda x: x%2, list1))
(out)[1, 3, 5, 9]
このfilter関数は内包表記やジェネレータ式を使用して以下のようにかける。ラムダ式を使うfilterよりもこの方が軽量であるとされる。
list2 = [x for x in list1 if x%2]
list2
(out)[1, 3, 5, 9]
list_iter = (x for x in list1 if x%2)
next(list_iter)
(out)1
next(list_iter)
(out)3
next(list_iter)
(out)5
next(list_iter)
(out)9
next(list_iter)
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)StopIteration
map
イテラブルなコレクションの全要素に一括で処理を適用できるmap関数が用意されている。
map( callable, iterable)
絶対値に変換する例を示す。mapもfilterと同じくiterableであるmapオブジェクトを返すため、リストとして使うためにはlist関数を使う。
lista = [-5, 10, 30]
list(map(abs, lista))
(out)[5, 10, 30]
このmap関数は内包表記やジェネレータ式を使用して以下のように書ける。
lista = [-5, 10, 30]
[abs(x) for x in lista]
(out)[5, 10, 30]
reversed
シーケンスを逆順に取り出すイテレータ(reverse iterator)を返す。
reversed( sequence )
使用例を示す。
datas = [10, 20, 30]
reversed(datas)
(out)<list_reverseiterator object at 0x000002B5A9925630>
for x in reversed(datas):
(con) print(x)
(con)
(out)30
(out)20
(out)10
この関数は順序がない(シーケンスでは無い)コレクションでは使用できない。
valueset = {1, 5, 3}
reversed(valueset)
(out)TypeError: 'set' object is not reversible
sorted
イテラブルなコレクションをソートしたリストを返す。元のコレクションは変更されない。
lista = [-30, 10, 5]
sorted( lista )
(out)[-30, 5, 10]
key引数でソートに使用するキーを、reverse引数で逆順(降順)にするかを指定できる。これは絶対値が降順となるようにソートする例である。
list_a = [-30, 10, 5]
sorted(list_a, key=lambda x:abs(x), reverse=True )
(out)[-30, 10, 5]
zip
複数のイテラブルなコレクションから値を一つずつ取り出したタプルを作成する。mapやfilterと同じくiterableなzipオブジェクトを返すため、リストとして使うためにはlist関数を使う。
iterable1 = (1,2,3)
iterable2 = ["M","F","M"]
iterable3 = ["Augustine","Onslow","Basil"]
list(zip(iterable1,iterable2,iterable3))
(out)[(1, 'M', 'Augustine'), (2, 'F', 'Onslow'), (3, 'M', 'Basil')]
コレクションの要素数が異なる場合、デフォルトでは最も要素数が少ないコレクションにあわせてタプルが作成される。strict引数をTrueにするとコレクションの長さが異なる場合にValueErrorが送出される。
iterable1 = (1,2,3)
iterable2 = ("A")
list(zip(iterable1, iterable2))
(out)[(1, 'A')]
list(zip(iterable1, iterable2, strict=True))
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)ValueError: zip() argument 2 is shorter than argument 1
要素数が長いコレクションに合わせてタプルを作成するためにはitertoolsライブラリのzip_longest(*iterables, fillvalue=None)が使用できる。
all
コレクションの要素が全てTrueに相当するときにTrueとなる。
dataset1 = [1, -5, 10, 2]
dataset2 = [6, 3, 0, 9]
all(dataset1)
(out)True
all(dataset2)
(out)False
dataset2にはFalseに相当する0が入っているため、Falseが返される。
リスト内包表記と併用すれば、全ての要素が何らかの条件を満たすか検査するときに使用できる。たとえば、全ての要素が0以上かどうか検査する例を示す。
all([x >= 0 for x in dataset1])
(out)False
all([x >= 0 for x in dataset2])
(out)True
any
コレクションの要素が1つでもTrueに相当するものがあるときにTrueとなる。
dataset1 = [1, -5, 10, 2]
dataset2 = [6, 3, 0, 9]
any(dataset1)
(out)True
any(dataset2)
(out)True
allと同じようにして、何らかの条件を満たす要素が1つでもあるか検査できる。0未満の要素があるかどうか検査する例を示す。
any([x < 0 for x in dataset1])
(out)True
any([x < 0 for x in dataset2])
(out)False
ジェネレータ
ジェネレータはイテレータを作成する方法の一つである。以下のようなyield文を含む関数をgenerator関数と呼ぶ。
def generator_function1():
yield 1
yield 2
yield 3
この関数を実行すると、戻り値としてgeneratorオブジェクトが得られる。
def generator_function1():
(con) yield 1
(con) yield 2
(con) yield 3
(con)
gen_iter = generator_function1()
gen_iter
(out)<generator object generator_function1 at 0x000001D5CE170E00>
このgeneratorオブジェクトはgenerator iteratorと呼ばれるイテレータの一種であり、for文などで使用できる。以下に例を示す。
for x in gen_iter:
(con) print(x)
(con)
(out)1
(out)2
(out)3
これを見るとgenerator iteratorはジェネレータ関数のyieldの後の値を順番に返すイテレータであることが分かる。
generator iteratorに対してnext()関数を実行すると、yield文に到達するまでの処理が実行される。yield文に到達すると処理は一時中断され、yieldに続く式の値を返す。再びnext()関数を実行すると中断時点から処理が再開され、また次のyield文に到達するまでの処理が実行される。もしyield文に到達しないで関数が終了した場合は、StopIteration例外が発生し終端に到達した扱いとなる。
gen_iter = generator_function1()
next(gen_iter)
(out)1
next(gen_iter)
(out)2
next(gen_iter)
(out)3
next(gen_iter)
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)StopIteration
Pythonのドキュメント等でコレクションの値を返すことが期待される関数で、戻り値がジェネレータであると書かれている場合、それはgenerator iteratorのことである。多くの場合ではイテラブルなオブジェクトであるとだけ理解しておけば実装上の不都合はないだろう。
例としてA_n=1,2,3,4,5,…と無限に続く数列を考えてみる。無限に続くため当然ながらリストで表すことはできないが、ジェネレータでは以下のように簡単に実現できる。
def generator_function2():
(con) a = 1
(con) while True:
(con) yield a
(con) a += 1
(con)
def generator_sample2():
(con) for i in generator_function2():
(con) print(i)
(con) if i >= 100: break # 無限に続くためループ側で終了するようにしておく
(con)
generator_sample2()
(out)1
(out)2
(out)(省略)
(out)99
(out)100
この例はジェネレータの特徴をよく表している。リストなどのイテレータはすでにあるコレクションから要素を順番にとりだすのに対し、ジェネレータは次の要素が必要になったときに要素を生成できる。そのため無限長の配列を作ることができる、メモリが少なくてすむなどの特徴がある。
generator iteratorの独自メソッド
generator iteratorは単純なイテレータとしてだけでなく、固有のsend、close、throwメソッドが使用できる。
send
sendメソッドではgenerator iteratorへ値を渡して、その値に基づいた次の値を生成させることができる。
def generator_function3():
(con) sum = 0
(con) while True:
(con) sent = yield sum
(con) if isinstance(sent, int):
(con) sum += int(sent)
(con) else:
(con) try:
(con) intvalue = int(sent)
(con) sum += intvalue
(con) except ValueError:
(con) pass
(con)
def generator_sample3():
(con) gen_iterator = generator_function3()
(con) sendvalue = None
(con) try:
(con) while True:
(con) x = gen_iterator.send(sendvalue)
(con) print(x)
(con) sendvalue = input("number:")
(con) except StopIteration:
(con) pass
(con) except EOFError:
(con) pass
(con) finally:
(con) gen_iterator.close()
(con)
generator_sample3()
(out)0
(out)number:3
(out)3
(out)number:5
(out)8
(out)number:2
(out)10
(out)number:Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out) File "<stdin>", line 8, in generator_sample3
(out)KeyboardInterrupt
このプログラムは数値の総合計を返すジェネレータである。ジェネレータに値を渡すにはfor...inやnextを使う代わりにsendメソッドを使う。generator iteratorの初回呼び出し、つまりyieldで一時中断になっていない状態では値を受け取ることができないため、send(None)としなければならない。
ポイントは4行目のsent = yield sumの所である。yieldで値を返すと同時に、次に生成するときに値をsendで受け取るようにしている。そして20行目のジェネレータを使っている側ではx = gen_iterator.send(sendvalue)で値を渡し、その結果をxに代入しているとういわけだ。
なお、nextを呼び出したときはNoneが渡された物として処理される。nextとsendを混ぜて使用しても問題ない。
throw
throwでジェネレータ側で例外を発生させることが出来る。ジェネレータが一時中断しているところ(通常はyieldの場所)で例外が発生した扱いとなる。ジェネレータ側で例外がキャッチされなかったり、例外処理中に別の例外が発生した場合は、throwの呼び出し側に戻って例外処理が行われる。
また、throwメソッドもnextと同様に次の値を生成してyieldで返すことが期待される。値を返すことなくジェネレータ側の処理が終了した場合はStopIteration例外が発生し終端に到達した扱いとなる。
close
closeメソッドを呼び出すと、ジェネレータが一時停止しているところ(通常はyieldの場所)でGeneratorExit例外が発生した扱いとなる。ジェネレータ側では、この例外をキャッチしクリーンアップ処理を行うことができる。
以下の場合、closeメソッドは正常に呼び出し元の処理に戻る。
- ジェネレータがこの例外を正しくキャッチし正常にクリーンアップが終了した場合
- ジェネレータがすでに終了していた場合
- GeneratorExit例外が発生した場合(発生した例外が処理されなかった場合も含む)
このcloseメソッドを呼び出したにも関わらずyieldで値が返された場合はRuntimeError例外が発生する。また、GeneratorExit以外の例外が発生した場合は普通のメソッドと同じく呼び出し元に通知される。
サブジェネレータ
ジェネレータにおいて、リストなどのイテラブルな値をyieldで一つずつ返すときはyield fromが利用できる。これをサブジェネレータとよぶ。
def generator_sample4():
yield from (1,2,3)
この例のgenerator_sample4は以下のgenerator_sample5と等価である。
def generator_sample5():
for num in (1,2,3):
yield num
ジェネレータ式
ジェネレータ式は簡易的にgenerator iteratorを作成する記法である。リスト内包表記と同じ表記方法を用いるが、()で囲む。
gen = (x for x in range(1, 4))
type(gen)
(out)<class 'generator'>
for i in gen:
(con) print(i)
(con)
(out)1
(out)2
(out)3
リスト内包表記と同様に複数のfor...inを記載できる。
gen_iter = ( (x,y) for x in (1,2) for y in (3,4) )
next(gen_iter)
(out)(1, 3)
next(gen_iter)
(out)(1, 4)
next(gen_iter)
(out)(2, 3)
next(gen_iter)
(out)(2, 4)
next(gen_iter)
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)StopIteration
列挙型
列挙型の基本
列挙型は「関連する定数を集めたり」「ユニークな値と関連付けられる名前を管理する」ときに使うものである。Pythonではenumモジュールで提供される。
色名を管理する列挙型の例を示す。列挙型はクラス方式とファンクション方式の2つの方法で作成できる。
from enum import Enum
# クラス方式
class Color(Enum):
RED = 1
GREEN = 2
BLUE = 3
# ファンクション方式
Color = Enum('Color', ['RED', 'GREEN', 'BLUE'])
「Color.RED」のようにアクセスしたり、対応する数値から名前を取り出すことができる。
Color = Enum('Color', ['RED', 'GREEN', 'BLUE'])
Color.RED
(out)<Color.RED: 1>
Color(1)
(out)<Color.RED: 1>
member = Color.RED
member.name
(out)'RED'
member.value
(out)1
Color(2).name
(out)'GREEN'
値の重複
Enumでは名前は重複できないが、値は重複しても良い。値が重複している場合、あとから定義されたものは先に定義された値の別名として扱われる。以下の例では1という値を持つ2つの名前:Color.REDとColor.KURENAIを定義している。Color.KURENAIを参照すると実体はColor.REDであることが分かる。
class Color(Enum):
(con) RED = 1
(con) KURENAI = 1
(con) BLUE = 2
(con)
Color(1)
(out)<Color.RED: 1>
Color.KURENAI
(out)<Color.RED: 1>
なお、Enumをイテレータで処理するときに別名は取り出されない。もし、別名も含めたすべての名前を取得したいならEnum.__members__を参照すると良い。
for c in Color:
(con) print(c)
(con)
(out)Color.RED
(out)Color.BLUE
for c in Color.__members__.items():
(con) print(c)
(con)
(out)('RED', <Color.RED: 1>)
(out)('KURENAI', <Color.RED: 1>)
(out)('BLUE', <Color.BLUE: 2>)
もし値が重複するべきでないのであれば、uniqueデコレータが利用できる。これは間違った値の設定防止に役に立つ。
from enum import Enum, unique
@unique
(con)class Color(Enum):
(con) RED = 1
(con) KURENAI = 1
(con) BLUE = 2
(con)
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out) File "C:\Users\name\AppData\Local\Programs\Python\Python312\Lib\enum.py", line 1594, in unique
(out) raise ValueError('duplicate values found in %r: %s' %
(out)ValueError: duplicate values found in <enum 'Color'>: KURENAI -> RED
値の自動設定
名前が統一されていることが重要であり、その値が何であるかが大きな意味を持たない場合、autoが指定できる。autoの挙動は_generate_next_value_()メソッドで制御できる。
from enum import Enum, auto
class Color(Enum):
RED = auto()
BLUE = auto()
GREEN = auto()
比較
列挙型はisや==/!=により等価性を評価できる。ただし順序は持たないため<=などの比較はできない。
Color.RED is Color.KURENAI
(out)True
Color.RED is not Color.BLUE
(out)True
Color.RED == Color.KURENAI
(out)True
Color.RED == 1
(out)False
Color.RED > Color.BLUE
(out)Traceback (most recent call last):
(out) File "<stdin>", line 1, in <module>
(out)TypeError: '>' not supported between instances of 'Color' and 'Color'
なお、Enumが定義されたモジュールの再読込が行われた場合、比較できなくなることがある。
# ColorEnumの定義
from enum import Enum
class Color(Enum):
RED = 0
BLUE = 1
GREEN = 2
import ColorEnum
from importlib import reload
redcolor1 = ColorEnum.Color.RED
reload(Enum1)
redcolor2 = ColorEnum.Color.RED
print(redcolor1 == redcolor2)
False派生型
Enumにはいくつかの派生型がある。ここでは簡単な紹介に留める。
| クラス名 | 特徴 |
|---|---|
| IntEnum | 整数のように振る舞うEnum。intのサブクラスでもある。 IntEnum同士は比較ができる。 |
| StrEnum | 文字列のように振る舞うEnum。strのサブクラスでもある。 |
| IntFlag | ビットフラグのように動作するEnum。intのサブクラスでもある。 ビット演算以外を行うとIntFlagではなくなる。 |
| Flag | フラグのように動作するEnum。 |
class UNIXPermission(IntFlag):
(con) R = 4
(con) W = 2
(con) X = 1
(con) RWX = 7 # これはR|W|Xの値と等しいのでエイリアス扱いとなる
(con)
UNIXPermission.R | UNIXPermission.W
(out)<UNIXPermission.R|W: 6>
UNIXPermission.RWX
(out)<UNIXPermission.RWX: 7>
UNIXPermission.R + UNIXPermission.W
(out)6
構造体
dataclass
構造体とは様々なデータをまとめたものである。Pythonの言語仕様に構造体そのものはないが、同等のことができるdataclassがPython 3.7から導入された。dataclassesモジュールからdataclassをインポートし、クラス定義の前に@dataclassデコレータを付ける。
from dataclasses import dataclass
@dataclass
class Human:
name: str
age: int
コンストラクタ
コンストラクは自動的に生成される。コンストラクタの引数の順序は定義順になる。
from dataclasses import dataclass
@dataclass
class Human:
name: str
age: int
h1 = Human("Eve", 0)
フィールドの初期値を設定することもでき、その場合はコンストラクタでも省略できる。
@dataclass
class Human:
name: str
age: int = 20
h1 = Human("test")
引数の制約を受けるため、初期値を設定したフィールドは後ろにまとめられていなければならない。以下は誤った指定の例である。
@dataclass
(con)class Human:
(con) name: str
(con) age: int = 20
(con) sex: str
(con)
(out)TypeError: non-default argument 'sex' follows default argument
コンストラクタ実行時になにか処理を行いたいなら__post_init__が使用できる。例えば他の要素により決定する要素を初期化できる。
@dataclass
class Human:
name: str
birth: date
age: int = field(init=False) # 初期化しないフィールド
def __post_init__(self):
pass # ここでbirthからageを計算する処理を実行
スペシャルメソッド
dataclassはいくつかのスペシャルメソッドを自動で実装する。実装するかどうかはデコレータで指定できる。デフォルトは以下の通り。
@dataclass(init=True, # __init__
repr=True, # __repr__
eq=True, # __eq__
order=False, # __lt__, __le__, __gt__, __ge__
unsafe_hash=False, # __hash__
frozen=False, # イミュータブル化
match_args=True, # __match_args__
kw_only=False, # すべての引数がキーワード専用引数になる
slots=False) # __slots__
field
dataclassでは以下のように初期値に空のlistを指定することができない。
@dataclass
(con)class Human:
(con) name: str
(con) age: int = 0
(con) address: list[str] = []
(con)
(out)ValueError: mutable default <class 'list'> for field address is not allowed: use default_factory
一部のフィールドではこのようなときに特別な設定が必要になる。たとえば特定のフィールドは一致しなくても同じとみなしたい場合もそうである。そのような特別な設定をするにはfiledを使用する。
dataclasses.field(*, default=MISSING, default_factory=MISSING, init=True, repr=True, hash=None, compare=True, metadata=None, kw_only=MISSING)
fieldを使用して初期値に空のリストを指定する例を示す。
from dataclasses import dataclass, field
@dataclass
class Human:
name: str
age: int
title: list[str] = field(default_factory=list)
以下は年齢を比較対象にせず、reprで表示もしないフィールド設定の例である。
from dataclasses import dataclass, field
@dataclass
(con)class Human1:
(con) name: str
(con) age: int = field(default=0, compare=False, repr=False)
(con)
@dataclass
(con)class Human2:
(con) name: str
(con) age: int = 0
(con)
h11 = Human1("Eve", 5); h12 = Human1("Eve", 10)
h21 = Human2("Eve", 5); h22 = Human2("Eve", 10)
f"{h11=}, {h12=}, {h21=}, {h22=}"
(out)"h11=Human1(name='Eve'), h12=Human1(name='Eve'), h21=Human2(name='Eve', age=5), h22=Human2(name='Eve', age=10)"
h11==h12
(out)True
h21==h22
(out)False
dataclassのエクスポート
作成したdataclassをJSONやYAMLに変換する方法として、Dataclass Wizardライブラリが利用できる。Dataclass Wizardライブラリは標準ライブラリではないためインストールが必要だ。なおYAMLならYAMLのライブラリであるruamel.yamlでも実現できるだろう。
py -m pip install dataclass-wizard使い方は簡単で、dataclassを作るときに指定のクラスを継承するだけだ。すると変換メソッドが呼び出せる形になる。YAMLならYAMLWizardになる。
from dataclasses import dataclass, field
import dataclass_wizard as dw
@dataclass
(con)class Human1(dw.YAMLWizard):
(con) name: str
(con) age: int = field(default=0, compare=False, repr=False)
(con)
h = Human1(name="Eve", age=30)
h_yaml = h.to_yaml()
h_load = Human1.from_yaml(h_yaml)
h == h_load
(out)True
h_yaml
(out)'age: 30\nname: Eve\n'
上記では文字列とdataclassを相互変換しているが、ファイルから入出力するメソッドも用意されている。
Dataclass Wizardのオプション
上の例ではYAMLに出力したHuman1のフィールド順序がクラス定義とは異なっていることが分かる。YAMLの変換ではPyYAMLを使っており、PyYAMLのオプションを指定できる。たとえばsort_keysでキーをアルファベット順にソートしないようにする。
>>> from dataclasses import dataclass, field >>> import dataclass_wizard as dw >>> >>> @dataclass ... class Human1(dw.YAMLWizard): ... name: str ... age: int = field(default=0, compare=False, repr=False) ... >>> h = Human1("Eve", 30) >>> h.to_yaml(sort_keys=False) 'name: Eve\nage: 30\n'